K-Means Clustering
1 Introduction
We have often heard of training machine learning models with labeled data. Imagine if there is a massive volume of data with no labels and we want to come up with a scalable approach to process these data and find insights. Difficult as it may seem, this is possible with clustering algorithms like K-Means.
Unsupervised machine learning is a type of algorithm that works on detecting patterns from a dataset when outcomes are not known or labeled. In unsupervised learning models it is not possible to train the algorithm the way we would normally do in case of supervised learning. The main reason for this is the kind of data available - a data set that is not labeled or classified and the algorithm must work on its own without any supervision. An unsupervised algorithm works on discovering the underlying hidden structure, pattern, or association of the data and that helps the model in clustering or grouping the data without any human intervention.
The main goal of this paper is to discuss the concept and underlying methodology of one the unsupervised algorithm called K-Means clustering. We will also discuss how K-Means can be leveraged in real time applications like customer segmentation (Yulin 2020). In this paper, we will also be discussing various limitations and bottlenecks of K-Means clustering algorithm and would suggest some improved algorithms to overcome these limitations.
1.1 K-Means Clustering
K-means clustering is used for grouping similar observations together by minimizing the Euclidean distance between them. It uses “centroids”. Initially, it randomly chooses K different points in the data and assigns every data point to their nearest centroid. Once all of them are assigned, it moves the centroid to the average of points assigned to it. When the assigned centroid stops changing, we get the converged data points in separate clusters.
1.2 Customer Segmentation
Customer segmentation helps divide customers into different groups based on their common set of characteristics (like age, gender, spending habit, credit score, etc.) that helps in targeting those customers for marketing purposes. The primary focus of customer segmentation is to come up with strategies that helps in identifying customers in each category to maximize the profit by optimizing the services and products. It’s all about connecting the right products with the right consumer keeping business profitability in mind. Most of the segmentation algorithm is based around analyzing what we call RFM - customer recency (i.e. when the customer last visited the store), frequency (i.e. how many times customer bought the products), and monetary (i.e. how much money the customer spent) (Tabianan 2022).
Customer segmentation is not only helpful for business but also helps customers by providing them information relevant to their needs. Customers can get really confused if we provide irrelevant information to them which has nothing to do with what products they are interested in or whatever purchasing habits they have. Unnecessary communications might cause customer attrition and may eventually lead to loss in business, revenue, and reputation. The customer segmentation using K-means clustering algorithm will help group customers as per their habits related to spending, purchasing or grouping them based on whatever product or brand the customers are interested in. Customer segmentation can be broadly divided into four factors - demographic psychographic, behavioral, and geographic(Tabianan 2022). In this paper, customer behavioral factor has been primarily focused.
Figure 1 illustrates the overall process of customer segmentation starting from sourcing the data, selecting the variables, applying the K-Means clustering to creating the marketing strategy for a business.
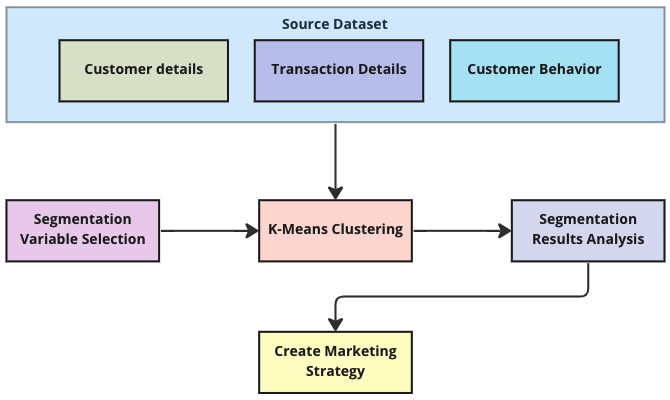
K-Means clustering algorithm can help effectively extract groups of customers with similar characteristics and purchasing behavior which in turn helps businesses to specify their differentiated marketing campaign and become more customer-centric.(Yulin 2020)
1.3 Limitations
One of the challenges of K-means clustering is determining an appropriate number of clusters, or the K-value. While this can be a challenge for datasets of any size, it is especially difficult to determine a reasonable K-value with very large datasets and those with high dimensionality, since it is much more difficult to visualize the data. The K-means clustering algorithm was developed in the 1960s, before the advent of the internet and the resulting era of big data, and as such, it was not designed for datasets of such large scale (Sinaga and Yang 2020).
Another limitation is the algorithm’s tendency to converge to only the local optimum solution, rather than the global minimum. The algorithm is sensitive to the initial centroid values selected, to noise, and to outliers, all of which can cause cluster centers to veer off, resulting in a local minimum solution (Jie et al. 2020).
The shape of data clusters is another concern. K-means clustering typically classifies n-hyperspherically shaped data well but is less successful at classifying irregularly shaped clusters (Ahmed, Seraj, and Islam 2020).
1.4 Improved K-Means
Researchers have developed methods to address the limitations of the K-means clustering algorithm.
One popular approach to determining an appropriate K-value is to use the “elbow method”. This method estimates K by calculating the sum of squared error (SSE) for a range of K-values; the SSE values are plotted against the K values. The point before the change in SSE becomes visually minimal (the elbow) is selected as the K-value (Nagaraj et al. 2022).
To overcome the challenge of selecting a K-value for very large datasets, researchers have developed a “novel unsupervised k-means (U-k-means) clustering algorithm.” This algorithm has a built-in process to determine the K-value and perform K-means clustering using the concept of entropy, and thus does not require any parameter initialization by the user. On the first iteration, the K-value is initialized as the number of data points. Gradually, extra clusters are discarded until the “best” number of clusters is found (Sinaga and Yang 2020).
Other researchers have developed methods utilizing data density to determine the K-value, approximate better initial cluster centroids, and detect outliers. For one proposed variation of the K-means algorithm, first, regional density is calculated using a CLIQUE grid (CLustering In QUEst). In the CLIQUE grid, each dimension is divided into equal parts and the number of data points is calculated within each cell. Cells with counts above a defined threshold are defined as dense units, and adjacent dense units are connected to determine regional density. Noise in areas of low density is removed. Next, a density-based clustering algorithm based on the Clustering by Fast Search and Find of Density Peaks (CFSFDP) algorithm is used to calculate the local density of each point to determine initial cluster centers. This method can be used with datasets of any shape and does not require that a K-value be initialized (Xu et al. 2020).
2 Methods
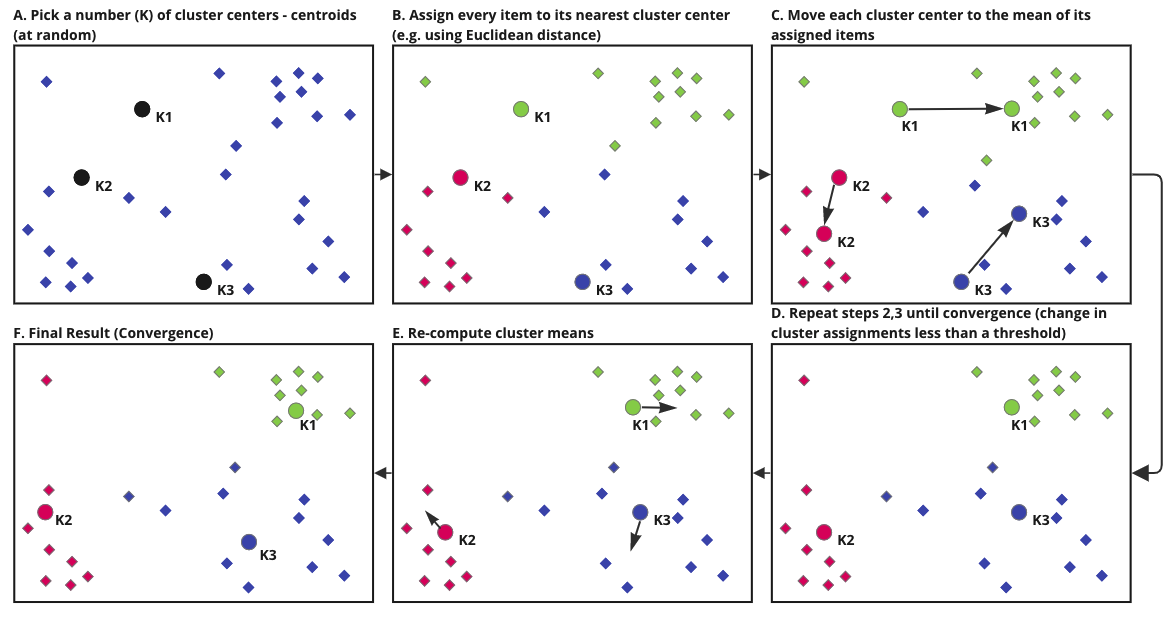
The methodology for K-Means involve multiple iterations performed with different initial cluster centers or means. However, in each round of the iteration, following steps are performed to achieve convergence(Stefanowski 2008):
- A random selection is made to assign initial centers (Shown as K1, K2 and K3)
- Distance between these initial centers and other points are analyzed. Points are assigned to appropriate clusters based on their distance from these center points
- New cluster centers are sought by finding the mean of the newly formed clusters. You can see how K1, K2 and K3 are shifting in this step
- Steps A, B and C are repeated in multiple iterations until there is no shift detected in the cluster centers K, K2 and K3
Let’s look at the mathematical implementation of this algorithm,
Proximity Measures
K-means calculates proximity between data points and centroids to place the data in appropriate cluster. There are several methods to calculate this proximity and the choice of the method plays a critical role in defining the shape of the cluster.
Euclidean distance measurement is the most general method used. However, there are several different calculations that can be used to measure inter and intra cluster proximities. Some of these methods are detailed below:
Euclidean distance:
\[ D_{euclidean}(x_1, x_2) = \sqrt{\sum_{i = 1}^{n}{((x_1)_i - (x_2)_i)^2}} \]
Manhattan distance:
\[ D_{manhattan}(x_1, x_2) = \sum_{i = 1}^{n}|((x_1)_i - (x_2)_i)| \]
\(x_1\), \(x_2\) are vectors of length n.
Algorithm
Suppose there is a dataset D that contains n data points and it was decided that there will be k clusters (and hence k initial cluster centers).(Yulin 2020)
\[ Z_j(I), j = 1, 2, 3...k. \]
Calculate the Euclidean distance between each data point and the cluster center, \(D(x_i, Z_j(I)), i = 1, 2...n; j = 1, 2...k.\), if below is satisfied:
\[ D(x_i, Z_k(I)) = min{D(x_i, Z_j(I)), j = 1, 2...n} \]
Now, calculate the new cluster center by calculating the error square sum criterion function J: changes
\[ J = \sum_{j = 1}^{k}\sum_{k = 1}^{n_j}||X_k^{(j)}-Z_j(I)||^2 \]
3 Analysis and Results
3.1 Dataset Description
For the customer segmentation, we will be using a data set that contains the transactions that has occurred for a UK-based non-brick-and-mortar online retail between 01/12/2009 and 09/12/2011. The company primarily offers unique gift-wares that can be used year-round on several occasions. Customers mostly buy from this store in wholesale. The company was established in 80s as a storefront and relied on direct mailing catalogs and taken order over phone. In recent years, the company launched a website and shifted completely to a web based online retail to take technological advantage of customer-centric targeted marketing approach(Chen 2010).
The customer transactions dataset has eight attributes as shown in below data definition table.
| Attribute | Type | Description |
|---|---|---|
| Invoice | Nominal | A 6-digit integral invoice number uniquely assigned to each transaction. A `c` prefix indicates a cancellation. |
| StockCode | Nominal | A 5-digit integral number uniquely assigned to each distinct product. |
| Description | Nominal | The detailed description of the product. |
| Quantity | Numeric | The quantities of each product per transaction. |
| InvoiceDate | Numeric | The day and time when a transaction has occurred and the invoice was generated. |
| Price | Numeric | Unit price of the Product in sterling (£). |
| CustomerID | Numeric | A 5-digit integral number uniquely assigned to each customer. |
| Country | Nominal | The name of the country where the transaction was made from. |
3.2 Load Data
Read the data from excel, load it and then summarize the column statistics.
| Invoice | StockCode | Description | Quantity | InvoiceDate | Price | CustomerID | Country |
|---|---|---|---|---|---|---|---|
| 489434 | 85048 | 15CM CHRISTMAS GLASS BALL 20 LIGHTS | 12 | 2009-12-01 07:45:00 | 6.95 | 13085 | United Kingdom |
| 489434 | 79323P | PINK CHERRY LIGHTS | 12 | 2009-12-01 07:45:00 | 6.75 | 13085 | United Kingdom |
| 489434 | 79323W | WHITE CHERRY LIGHTS | 12 | 2009-12-01 07:45:00 | 6.75 | 13085 | United Kingdom |
| 489434 | 22041 | RECORD FRAME 7" SINGLE SIZE | 48 | 2009-12-01 07:45:00 | 2.10 | 13085 | United Kingdom |
| 489434 | 21232 | STRAWBERRY CERAMIC TRINKET BOX | 24 | 2009-12-01 07:45:00 | 1.25 | 13085 | United Kingdom |
| 489434 | 22064 | PINK DOUGHNUT TRINKET POT | 24 | 2009-12-01 07:45:00 | 1.65 | 13085 | United Kingdom |
Let us check the distribution of each field by doing univariate analysis.
Plot:
- Bar chart for categorical attributes
- Histogram for numeric attributes
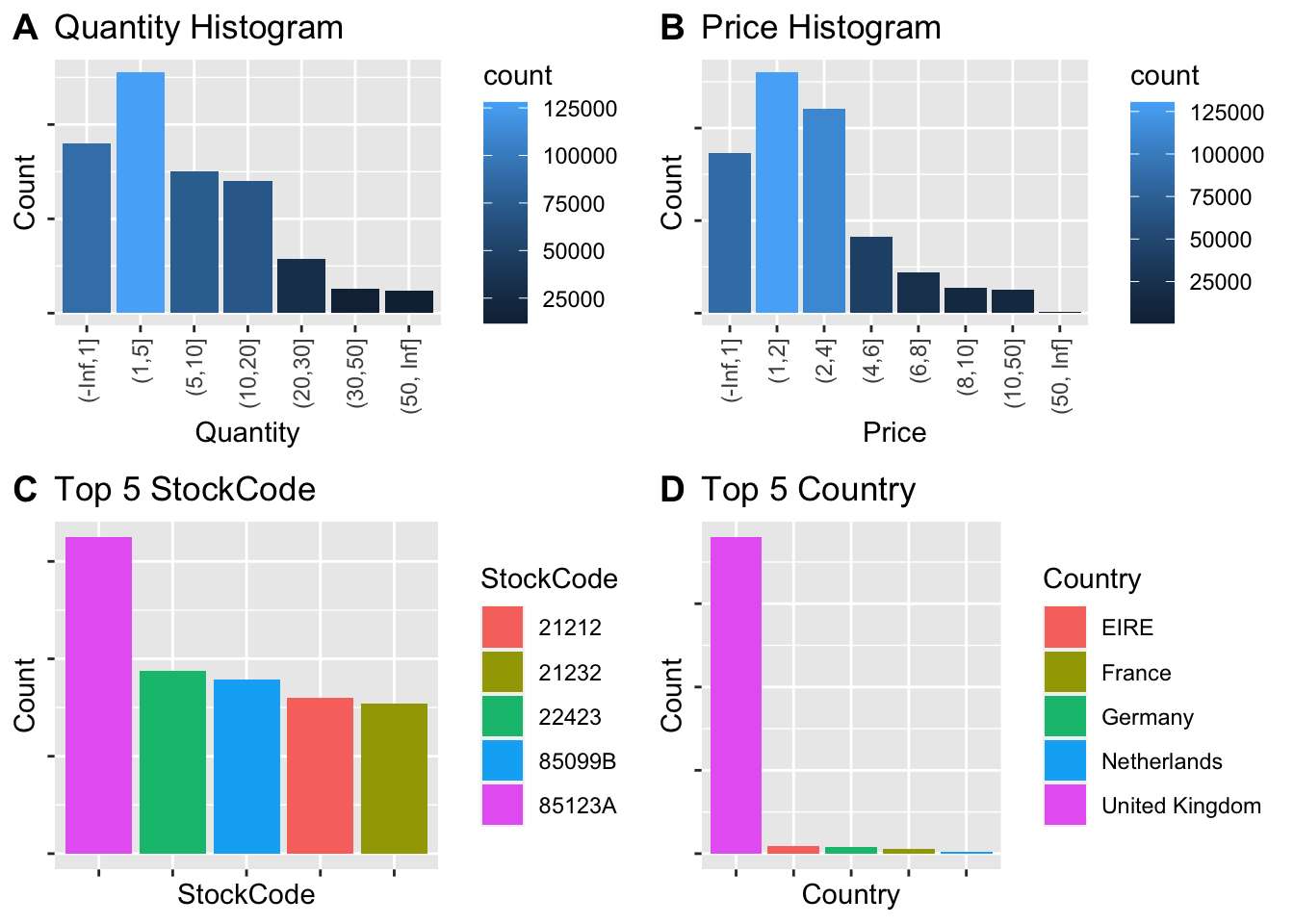
From the visualizations, we get a good amount of information about the structure of our chosen data. Below are the observations:
- The Quantity is heavily skewed right and most of the transactions involved a quantity in the range of 1 to 5
- The unit Price is also skewed right and most of the items have unit price between 1 and 4
- The item with StockCode 85123A was sold most
- Most of the customers belong to United Kingdom
3.3 Data Preparation
Before we prepare the data, let’s look at the summary and see if there are any missing values or other trends.
| N | Missing | Mean | SD | Min | Q1 | Median | Q3 | Max | |
|---|---|---|---|---|---|---|---|---|---|
| Quantity | 525461 | 0 | 10.34 | 107.42 | -9600.00 | 1.00 | 3.0 | 10.00 | 19152.00 |
| Price | 525461 | 0 | 4.69 | 146.13 | -53594.36 | 1.25 | 2.1 | 4.21 | 25111.09 |
| Customer Id | 417534 | 107927 | - | - | - | - | - | - | - |
For conducting our analysis, we will be applying below listed data pre-processing steps on the original dataset:
- The CustomerID contains unique Id for each unique Customer. However, we have 107,927 customers with no customer ids. We will be removing these customers before starting our analysis. After removing these customers with no ids, the total records are 417, 534.
Code
#remove missing values
df=na.omit(df, cols="CustomerID")- Select appropriate attributes that helps in our analysis - CustomerID, Invoice, Quantity, InvoiceDate and Price
Code
#remove description
data = subset(df, select = -c(Description, Country, StockCode) )- Create a new attribute Amount. This will help in clustering these customers by the total money spent. Group the data by customer id to obtain each unique customer and the total amount spent by them
Code
#Create a new attribute Amount
data$Amount = data$Quantity * data$Price
#Group by customer id and add amounts
customer_monetary <- as.data.frame(data %>%
group_by(CustomerID) %>%
summarise(Amount = sum(Amount)))- Group the data by customer id to get each unique customer and the number of times (Frequency) they visited the store (by counting their number of invoices)
Code
#Group by customer id and count invoices
customer_frequency <- as.data.frame(data %>% group_by(CustomerID) %>% summarise(Invoice = n()))
#Change the name of the aggregated invoice attribute to a more appropriate name "frequency"
names(customer_frequency)[names(customer_frequency) == "Invoice"] <- "Frequency"- Create a new attribute LastSeen. This will be calculated by subtracting the InvoiceDate from the max (InvoiceDate) and will show how many days have passed since the customer was last seen shopping. Group the data by customer id to get each unique customer and the minimum of the LastSeen.
Code
#Create a new attribute LastSeen
data$LastSeen =as.integer(difftime(max(data$InvoiceDate), data$InvoiceDate, units = "days"))
#Group by customer id and take min of LastSeen
customer_lastseen <- as.data.frame(data %>% group_by(CustomerID) %>% summarise(LastSeen = min(LastSeen)))- Merge the above data frames to get unique customer and their total amount, frequency of visit to the store and the LastSeen shopping in the store
Code
#merge newly created attributes to form a new dataset customer
customer <- merge(customer_monetary, customer_frequency, by = 'CustomerID')
customer <- merge(customer, customer_lastseen, by = 'CustomerID')- Detect outliers and remove them. To create meaningful clusters, we will be removing outliers from numeric columns Amount, Invoice and LastSeen
Code
melt(customer[,2:4]) %>% ggplot(aes(x=variable, y=value)) + geom_boxplot(aes(fill=variable), outlier.colour = NULL) + theme(legend.position="none")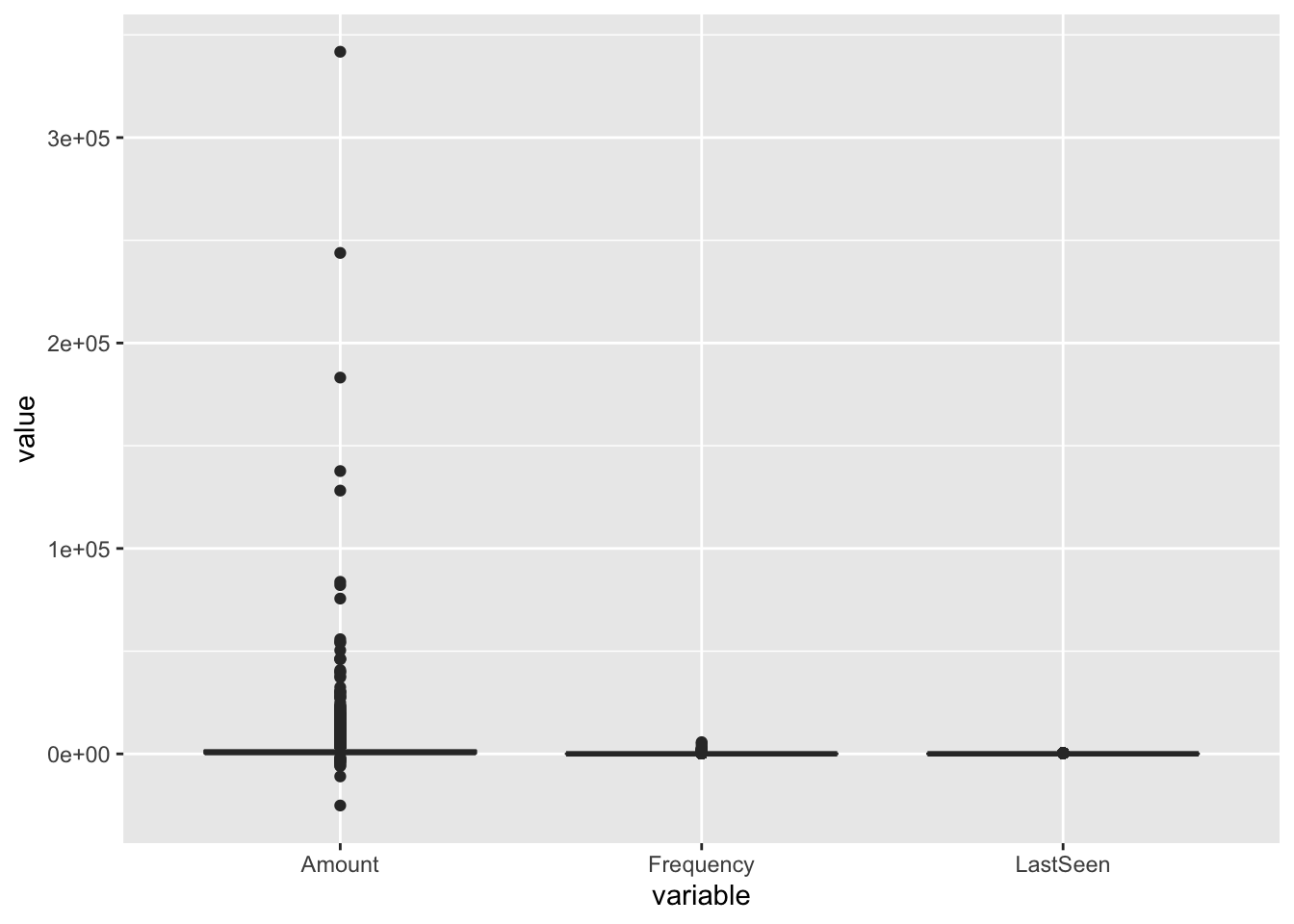
Above graph shows that there are outliers that need to be addressed to get accurate clustering results.
Code
# create a method to detect outliers
detectOutliers <- function(d) {
# calculate 25 percentile (Q1)
Q1 <- quantile(d, probs=.25)
# calculate 75 percentile (Q3)
Q3 <- quantile(d, probs=.75)
# Determine the IQR (Inter Quartile Range)
IQR = Q3-Q1
# Return a Boolean if input falls out of range
d > Q3 + (IQR*1.5) | d < Q1 - (IQR*1.5)
}
# create a method for eliminating outliers
eliminateOutlier <- function(df,
cols=names(df)) {
# Loop through each column in the columns vector
for (col in cols) {
# eliminate the item if detectOutliers returns true
df <- df[!detectOutliers(df[[col]]), ]
}
return(df)
}
# detectOutliers(customer$Amount)
customer <- eliminateOutlier(customer, c('Amount','Frequency','LastSeen'))Now, after removing outliers and cleaning up the data, we see normal distribution of the Amount, Frequency and LastSeen columns.
Code
melt(customer[,2:4]) %>% ggplot(aes(x=variable, y=value)) + geom_boxplot(aes(fill=variable), outlier.colour = NULL) + theme(legend.position="none")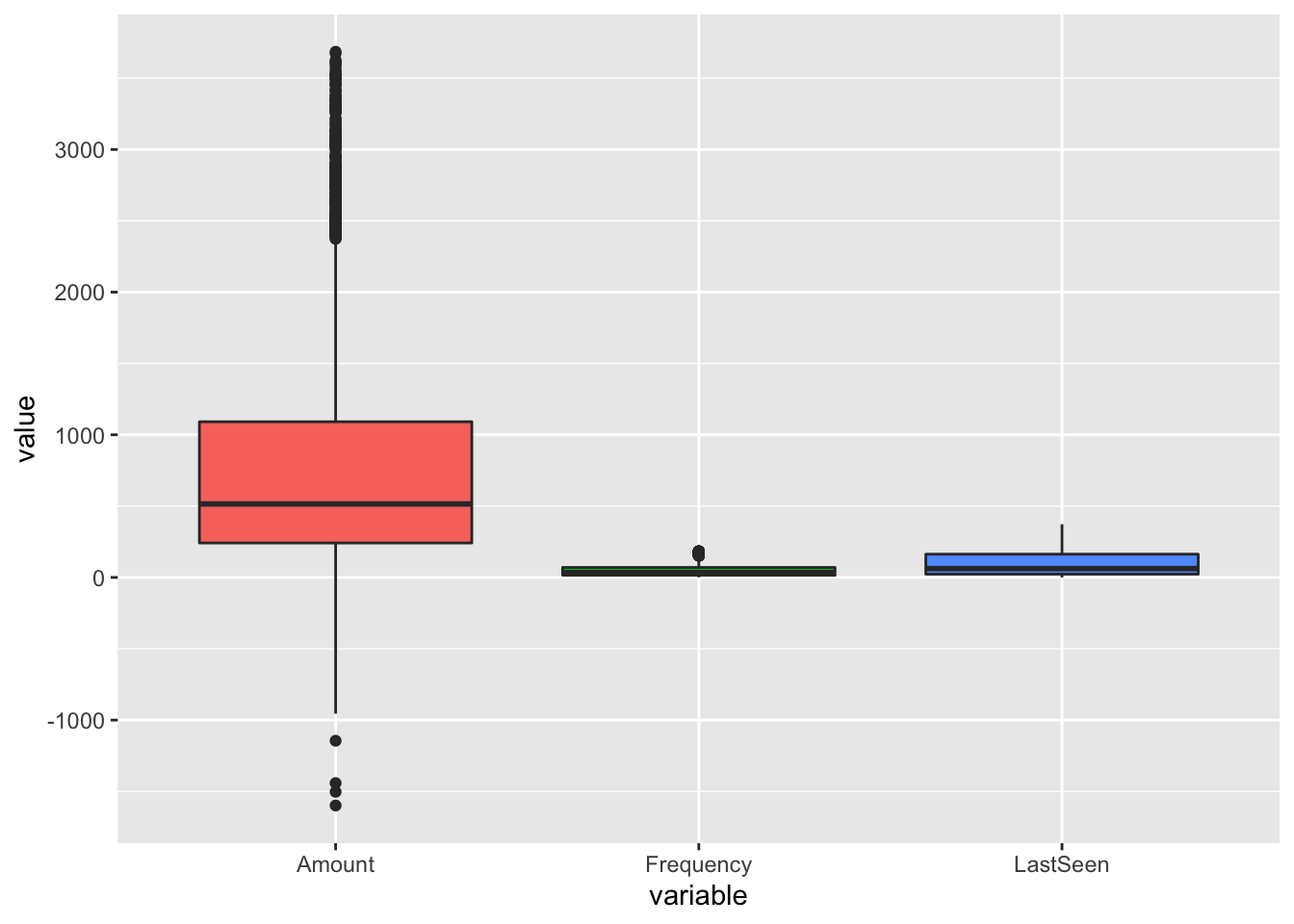
- Scale the data. It is very important to standardize the data by scaling the columns as the K-Means algorithm utilizes the proximity of data points based on the Euclidean distance.
Code
#copy customer dataset into a new dataset customer_details
customer_details <- customer
#Remove CustomerID attribute from customer for analysis
customer <- customer %>% select(-CustomerID)
# scale numeric attributes
customer_scaled <- customer %>% mutate_at(c("Amount", "Frequency", "LastSeen"), ~(scale(.) %>% as.vector))3.4 Target Dataset Analysis
We started our analysis with total 525461 records but after preparing and cleansing the data, we are left with total 3674 records to be analyzed.
| Attribute | Type | Description |
|---|---|---|
| CustomerID | Numeric | A 5-digit integral number uniquely assigned to each customer. |
| Amount | Numeric | Total Amount spent by each unique customer |
| Frequency | Numeric | Number of times customer made purchases bases on their invoice. |
| LastSeen | Numeric | Days elapsed since the customer was last seen shopping. |
| Mean | Min | Q1 | Median | Q3 | Max | |
|---|---|---|---|---|---|---|
| Amount | 776.5 | -1598.7 | 241.5 | 515.1 | 1091.4 | 3685.1 |
| Frequency | 48.15 | 1 | 15.0 | 34.0 | 70.0 | 183.0 |
| LastSeen | 101.8 | 0 | 23.0 | 62.0 | 163.0 | 373.0 |
3.5 Statistical Modeling
3.5.1 Optimal Number of Clusters (K)
One of the challenges in the K-Means clustering is determining initial value of K to ensure the resulting solution actually represents the underlying structure in the data. The reliability and the efficiency of the K-Means clustering algorithm is directly impacted by the choice of the number of clusters (K).
3.5.1.1 Elbow Method
We will be using a popular method called Elbow Method to determine the optimal value of K. The underlying idea behind this method is that it calculates values of within cluster sum of squares (WCSS) with the changing value of K. As the value of K increases, the cluster will have fewer data points and the distortion (within cluster sum of square) will decrease. The larger number of clusters (and hence the lesser number of data points within the cluster) implies the data points are closer to the centroid. The point where a sudden drop in this distortion is detected, is the elbow point(STEINLEY 2011). The name comes from the shape of the graph formed.
Code
fviz_nbclust(customer_scaled, kmeans, method = "wss") +
geom_vline(xintercept = 3, linetype = 2)+
labs(subtitle = "Elbow Method")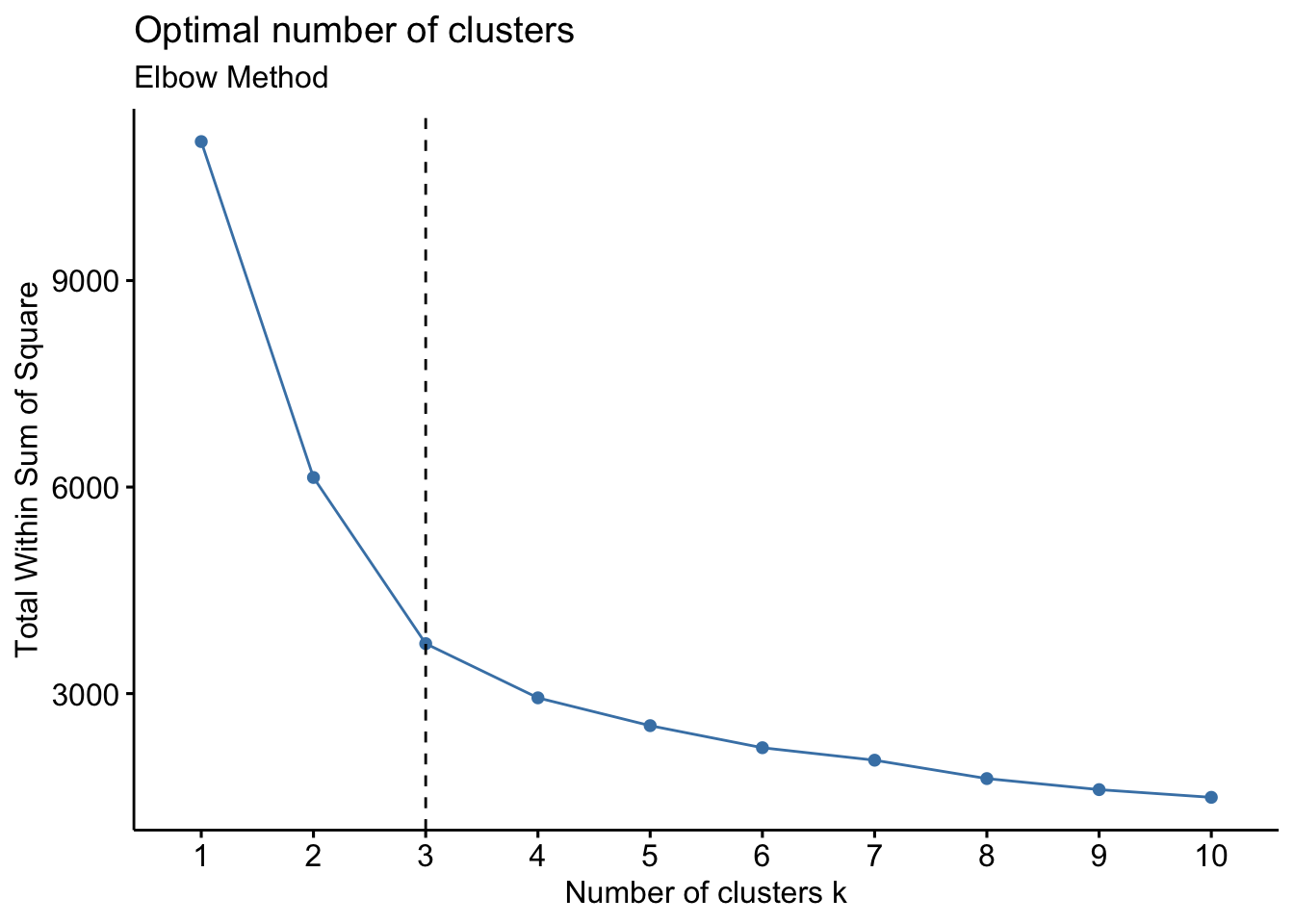
3.5.1.2 Silhouette Method
Another way to find the optimal number of clusters in K-Means is Silhouette Method. We will be using it to double check the results we obtained from the above Elbow method. The silhouette method calculates a coefficient (called silhouette coefficient) which is a measure of how similar a data point is within-cluster (cohesion) compared to other clusters (separation).(Li 2013)
Code
fviz_nbclust(customer_scaled, kmeans, method = "silhouette")+ theme_classic()+
labs(subtitle = "Silhouette Method")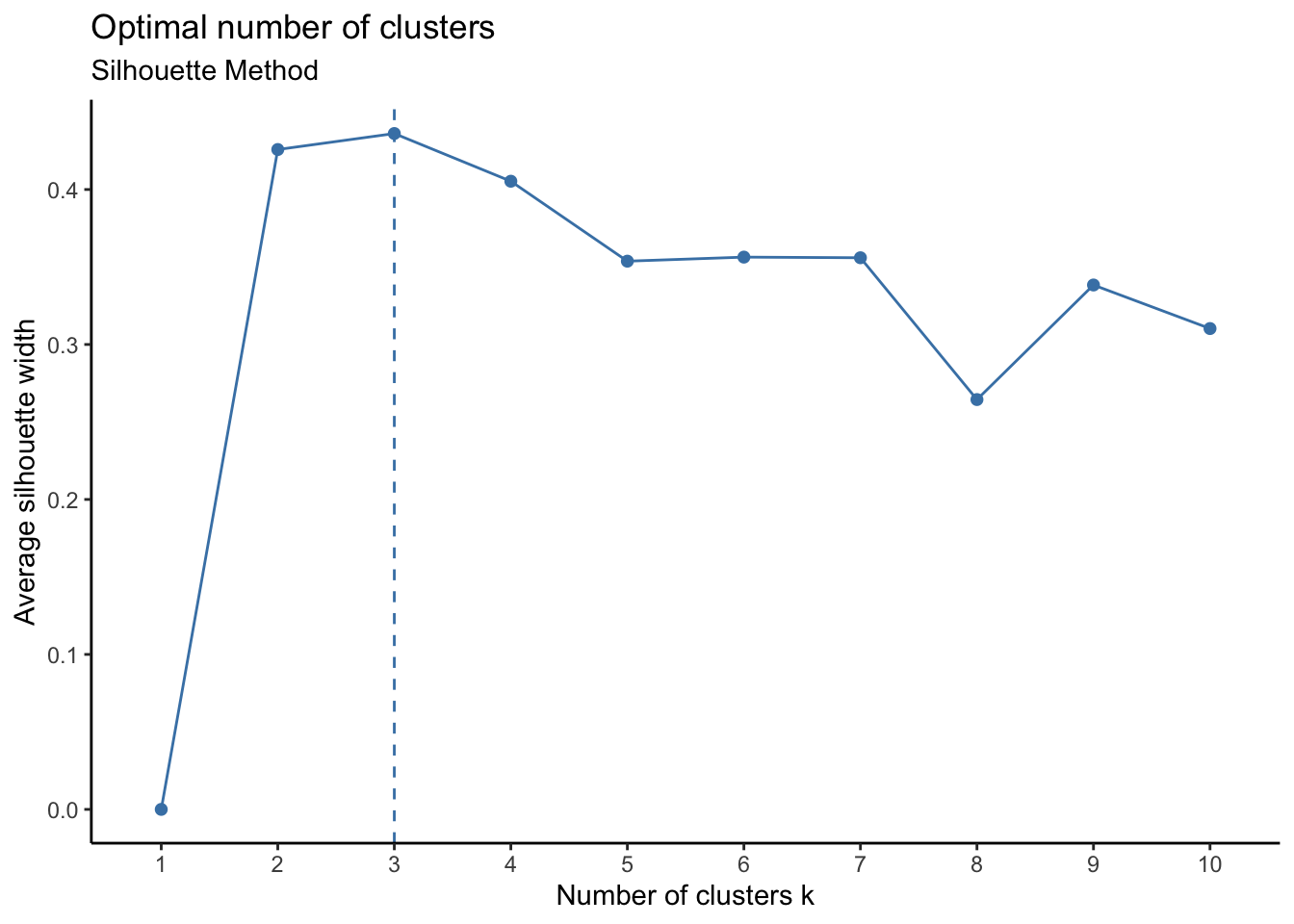
3.5.1.3 Gap Statistic Method
Gap Statistics relies on an approach where the number K is chosen based on the biggest fluctuation in the within-cluster distance.(R. Tibshirani and Hastie 2001)
Code
set.seed(123)
gap_stat <- clusGap(customer_scaled, FUN = kmeans, nstart = 25, K.max = 10, B = 50)
fviz_gap_stat(gap_stat)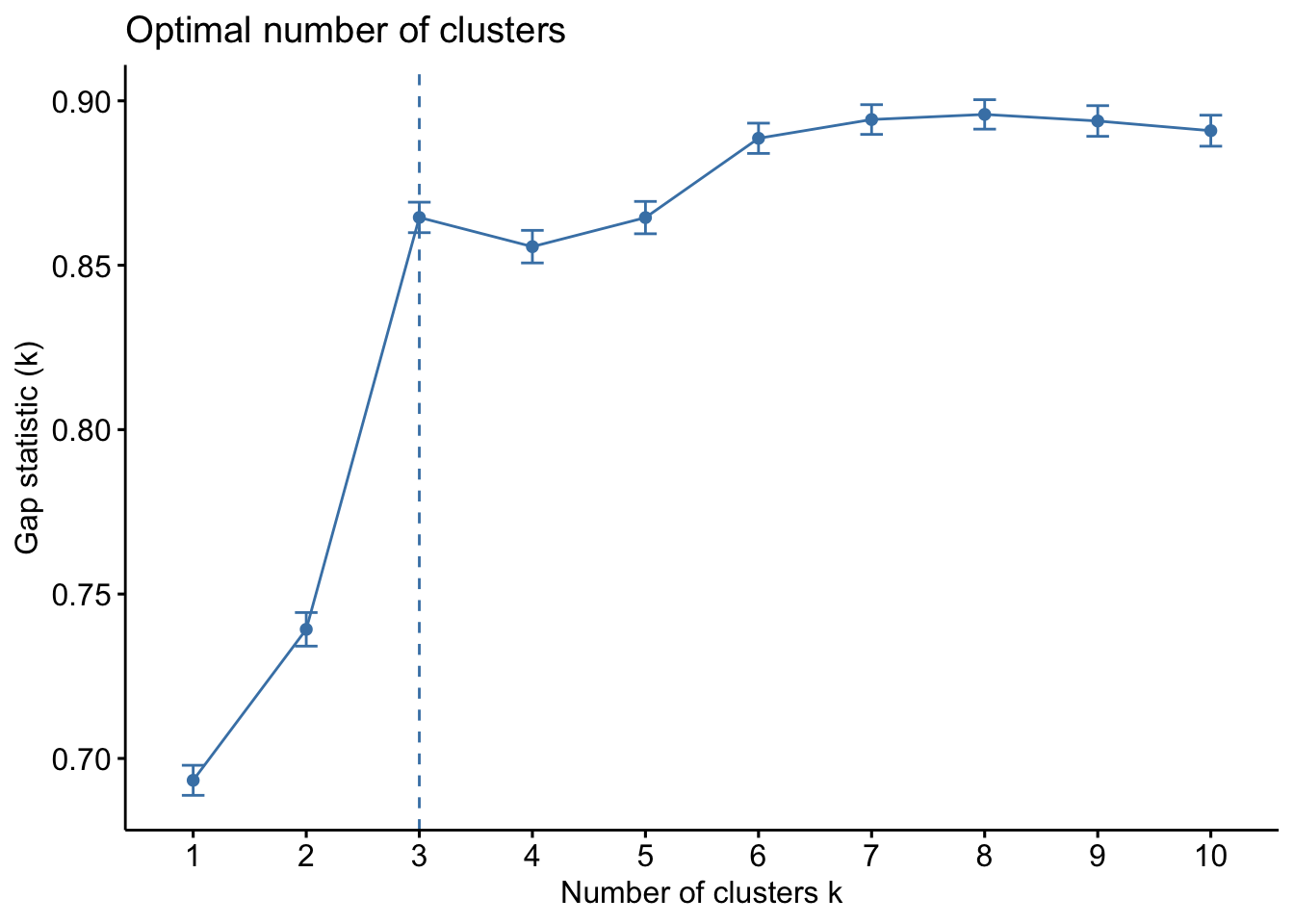
From the above graphs for Elbow, Silhouette and Gap Statistics methods, we can observe the critical point is at ‘3’. So, we will pick 3 as our k value for number of clusters.
\[ K = 3 \]
3.5.2 K-Means Model
Now, we will create the K-Means model with K = 3.
Code
# Compute k-means with k = 3
set.seed(123)
k = 3
m1.kmean <- customer_scaled %>% kmeans(k, iter.max = 20, nstart = 25)
#nstart: Runs multiple initial configurations and returns the best one.
#Add Clusters to the original dataframe
customer$Cluster <- as.factor(m1.kmean$cluster)The model results in 3 clusters as was decided and the clusters are formed with sizes 1807, 953, 914.
Now, we can extract the clusters and add to our initial data to do some descriptive statistics at the cluster level. Below table summarizes the original dataset grouped by clusters to show the mean of the variables:
Code
clustStats <- customer %>%
group_by(Cluster) %>%
summarise_all("mean")
clustStats %>%
kbl() %>%
kable_paper("hover", full_width = T)| Cluster | Amount | Frequency | LastSeen |
|---|---|---|---|
| 1 | 514.2098 | 32.46375 | 51.45102 |
| 2 | 309.8873 | 21.64953 | 251.48478 |
| 3 | 1781.5403 | 106.80197 | 45.15536 |
Code
fviz_cluster(m1.kmean, data = customer_scaled,
palette = c("#2E9FDF", "#00AFBB", "#E7B800"),
geom = "point",
ellipse.type = "convex",
ggtheme = theme_bw()
)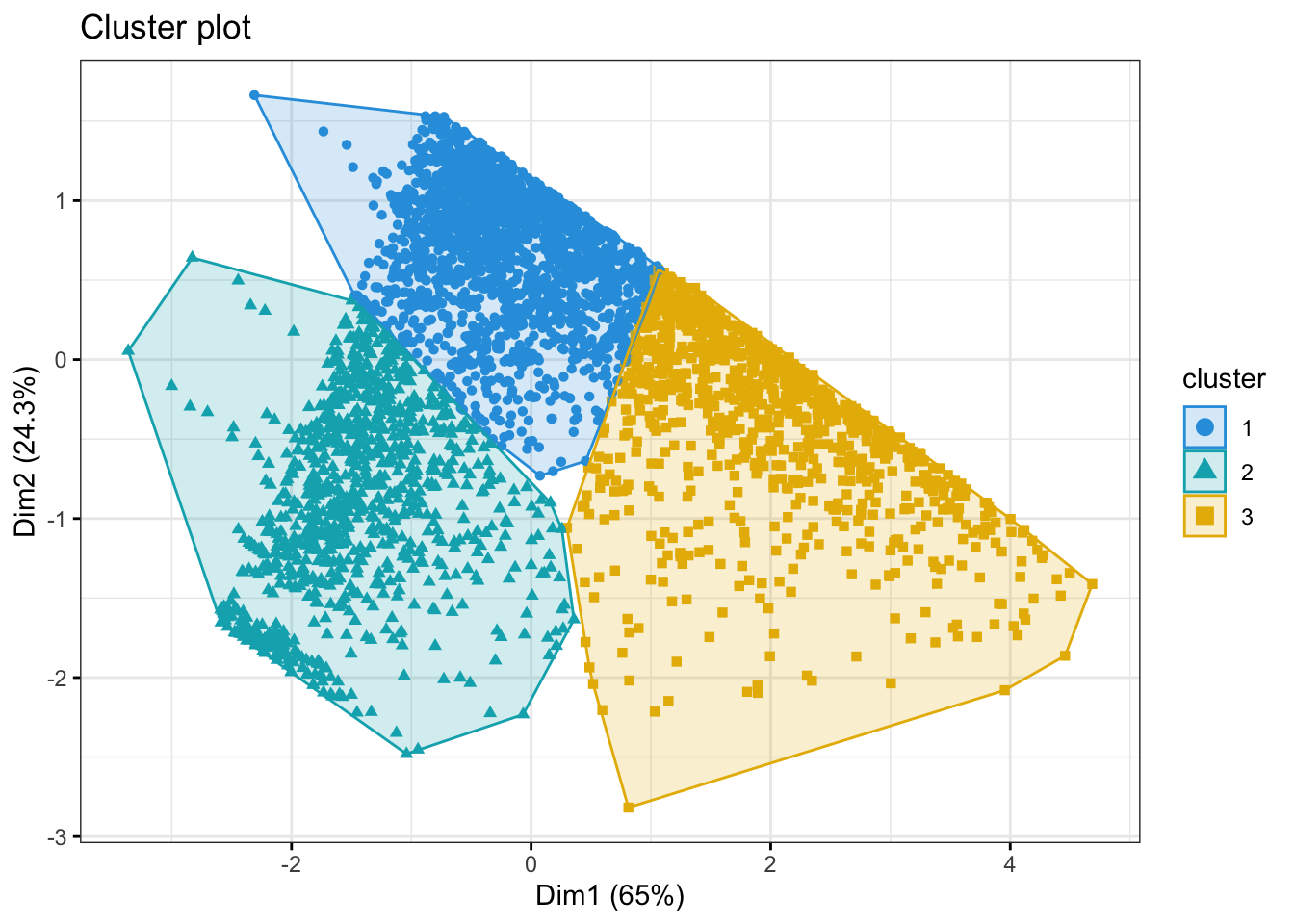
The above graph shows the clusters created using all columns of customer dataframe using the first two principle components to define the X-Y coordinates of each observation.
Code
fviz_cluster(m1.kmean, data = customer_scaled,choose.vars = c("LastSeen","Amount"),
palette = c("#2E9FDF", "#00AFBB", "#E7B800"),
geom = "point",
ellipse.type = "convex",
ggtheme = theme_bw()
)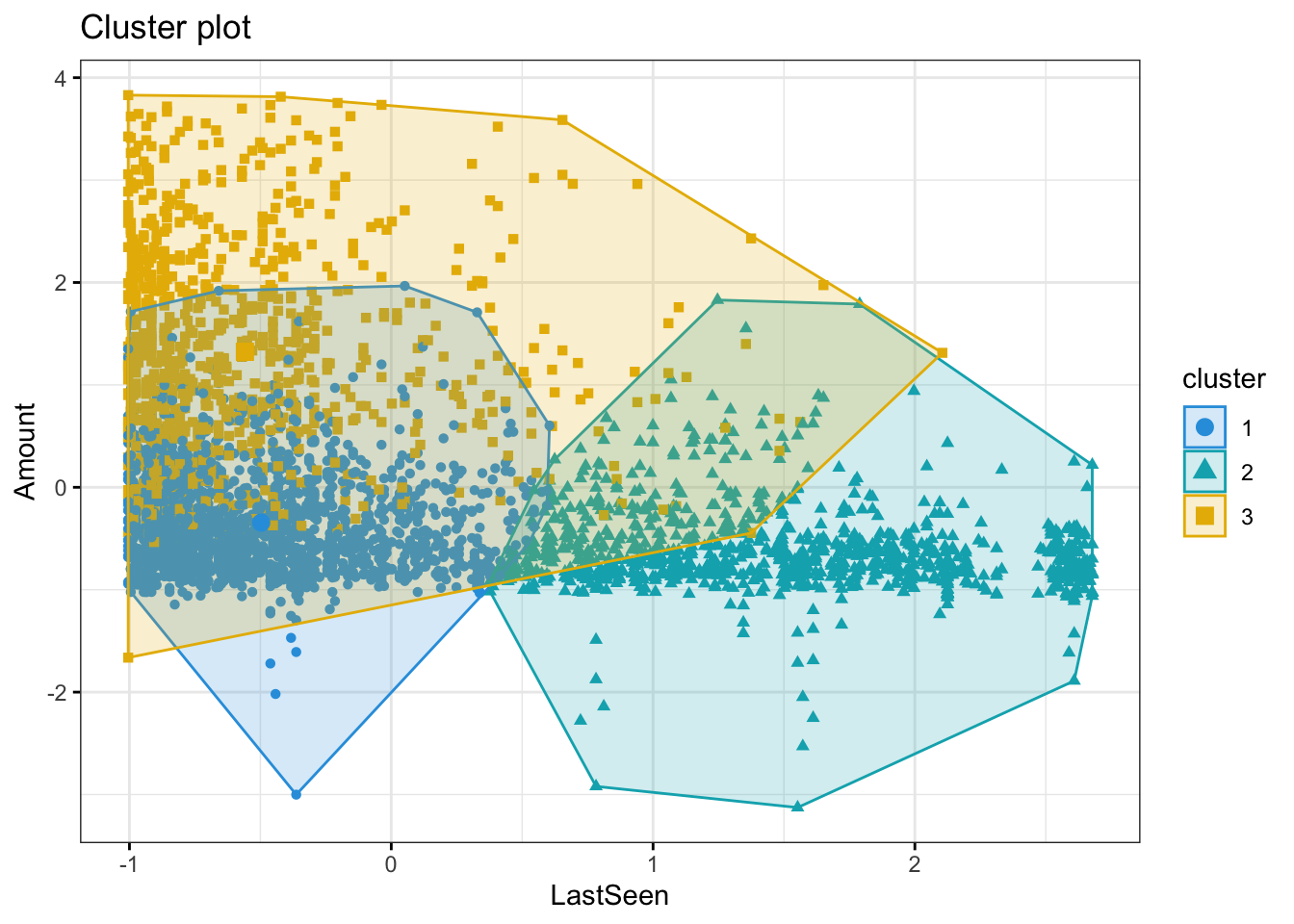
The above graph shows that the clusters 1 and 3 are seen in the store often. Cluster 3 customers are spending more whenever they visit. Cluster 2 not seen recently so spend less.
Code
fviz_cluster(m1.kmean, data = customer_scaled,choose.vars = c("Frequency","Amount"),
palette = c("#2E9FDF", "#00AFBB", "#E7B800"),
geom = "point",
ellipse.type = "convex",
ggtheme = theme_bw()
)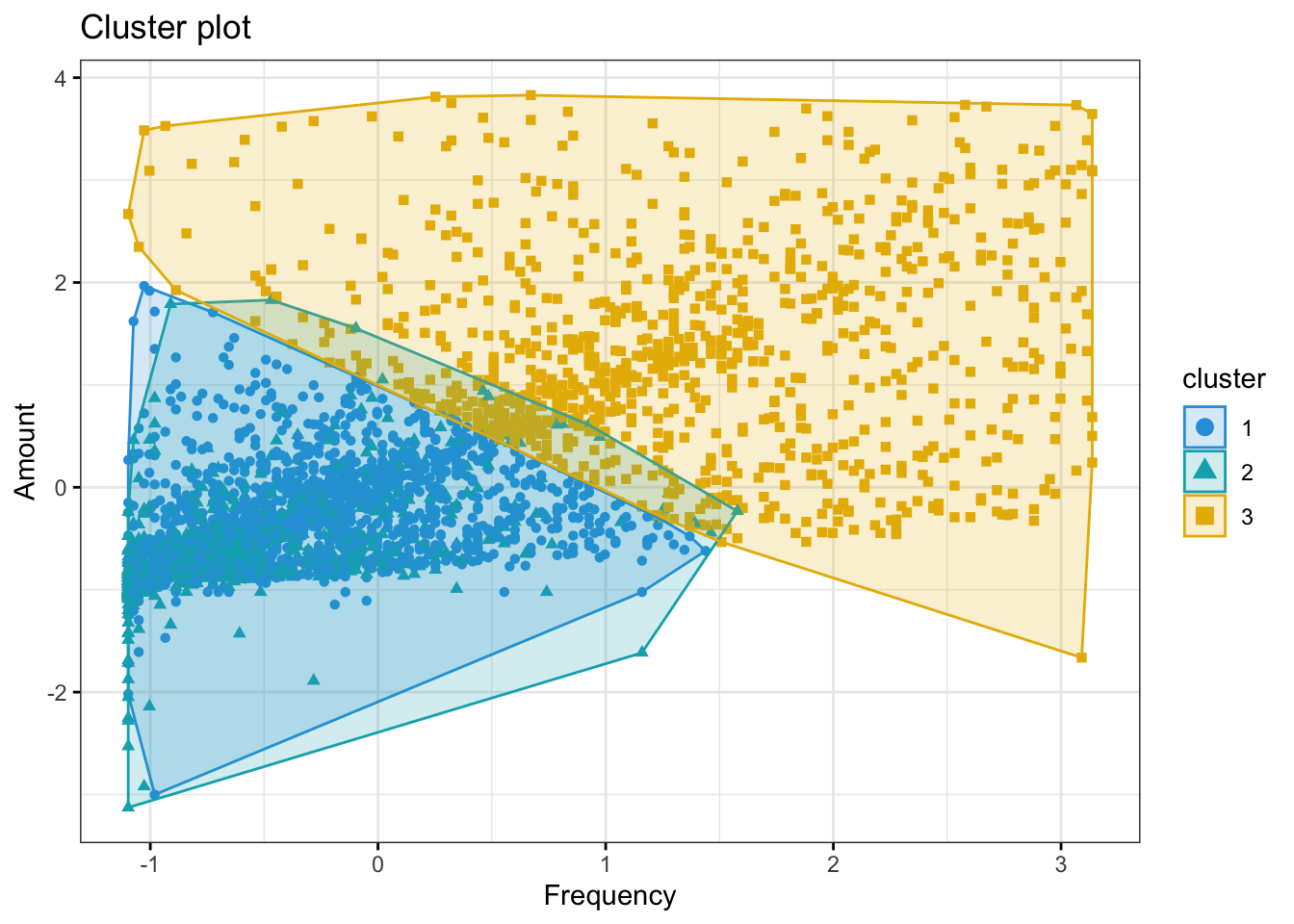
The above graph shows that the Cluster 3 are more frequently buying and hence spending more. Cluster 1 and 2 are almost having similar trends in terms of number of purchases and amount spent.
Code
fviz_cluster(m1.kmean, data = customer_scaled,choose.vars = c("LastSeen","Frequency"),
palette = c("#2E9FDF", "#00AFBB", "#E7B800"),
geom = "point",
ellipse.type = "convex",
ggtheme = theme_bw()
) 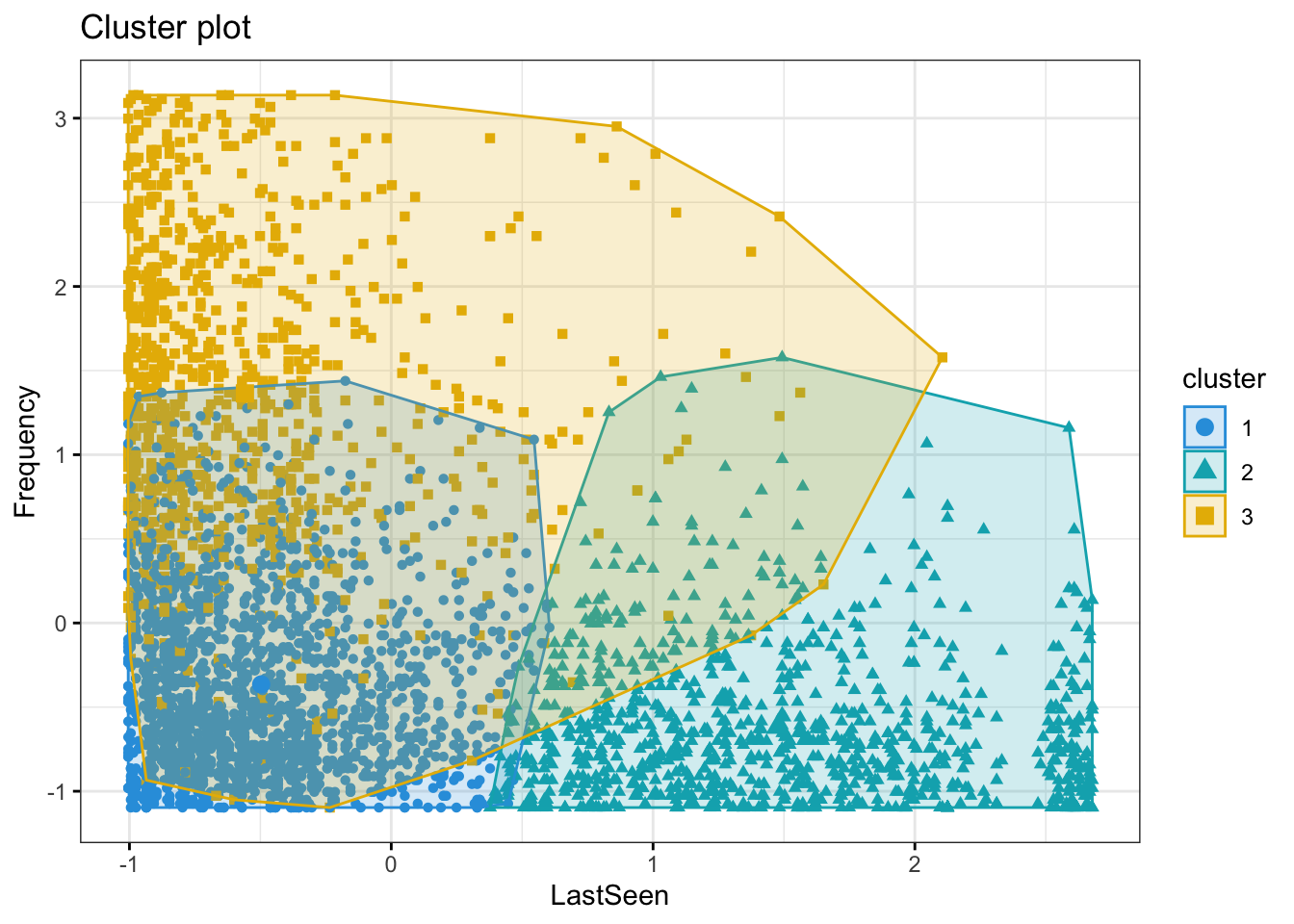
The above graph shows that the Cluster 1 and 3 are seen buying often and whenever they are seen buying, they make lot of purchases.
Code
colors <- c("#9f00e6", "#e69f00", "#00e69f")
colors <- colors[as.numeric(m1.kmean$cluster)]
s3d <- scatterplot3d(customer_scaled, pch = 16, color=colors)
legend("top",legend = paste("Cluster", 1:3),
col = c("#9f00e6", "#e69f00", "#00e69f"), pch = 16)
centers <- data.frame(m1.kmean$centers)
s3dp <- s3d$points3d(centers,
col = c("#000000","#0e0a00","#000e0a"), type = "h", pch = 8)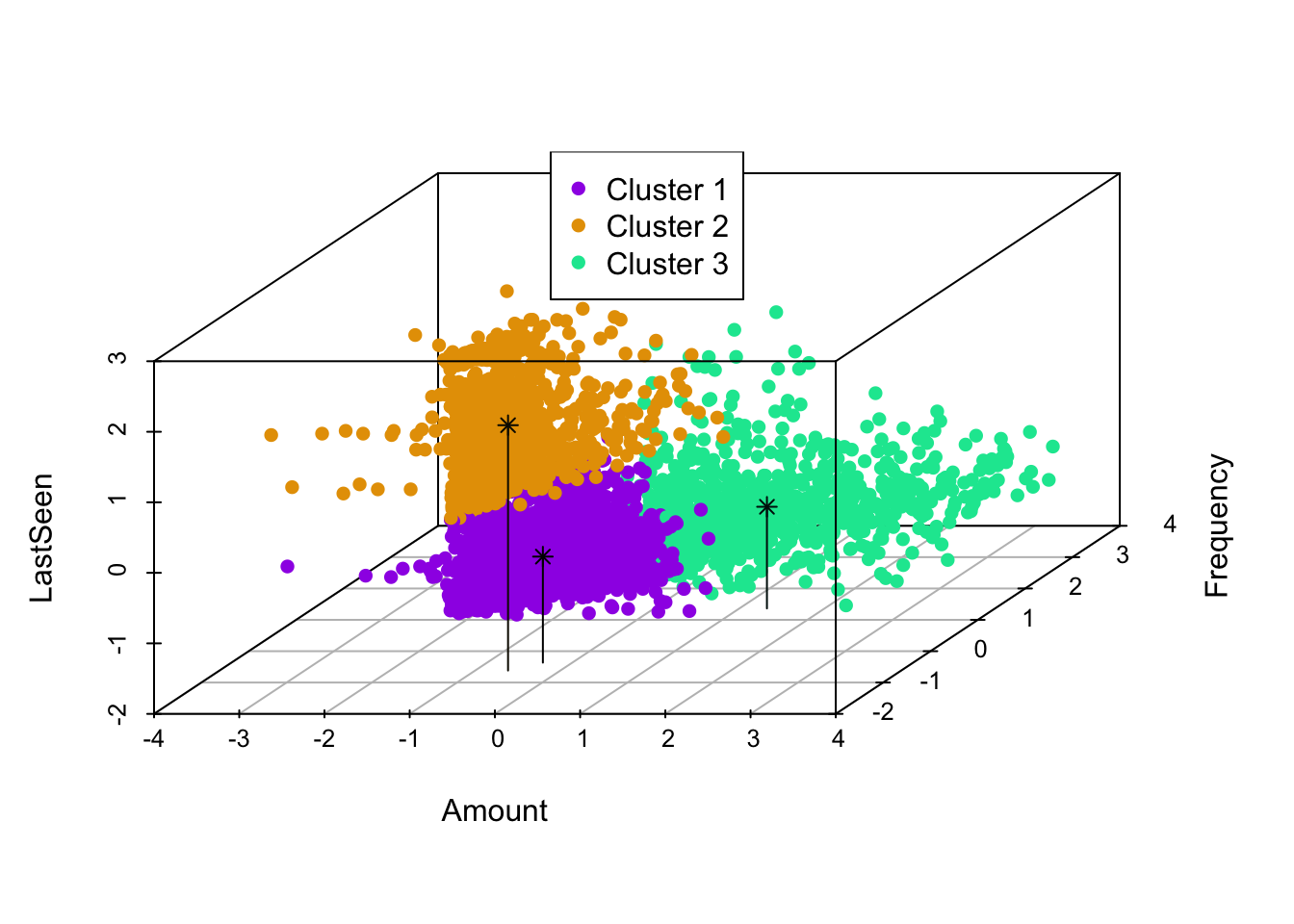
From the above graph that depicts all the three dimensions of the clustering, we can clearly see that the customers in cluster 3 are seen shopping often, they spend more, and they purchase frequently.
Customers in cluster 2 are of concern. They do not visit the website often but spend almost like cluster 1 and purchase as frequently as cluster 1. So, we can either target cluster 1 to make them buy when they visit store (since they are visiting often but buying less) or make cluster 2 visit often as they are buying more when they visit but visiting less.
Code
customer %>% ggplot(aes(x=Cluster, y=Amount, fill=Cluster)) + geom_boxplot()+ theme_classic() +
labs(title = "Clusters based on Amount Spent", subtitle = "K-Means Model m1.kmeans")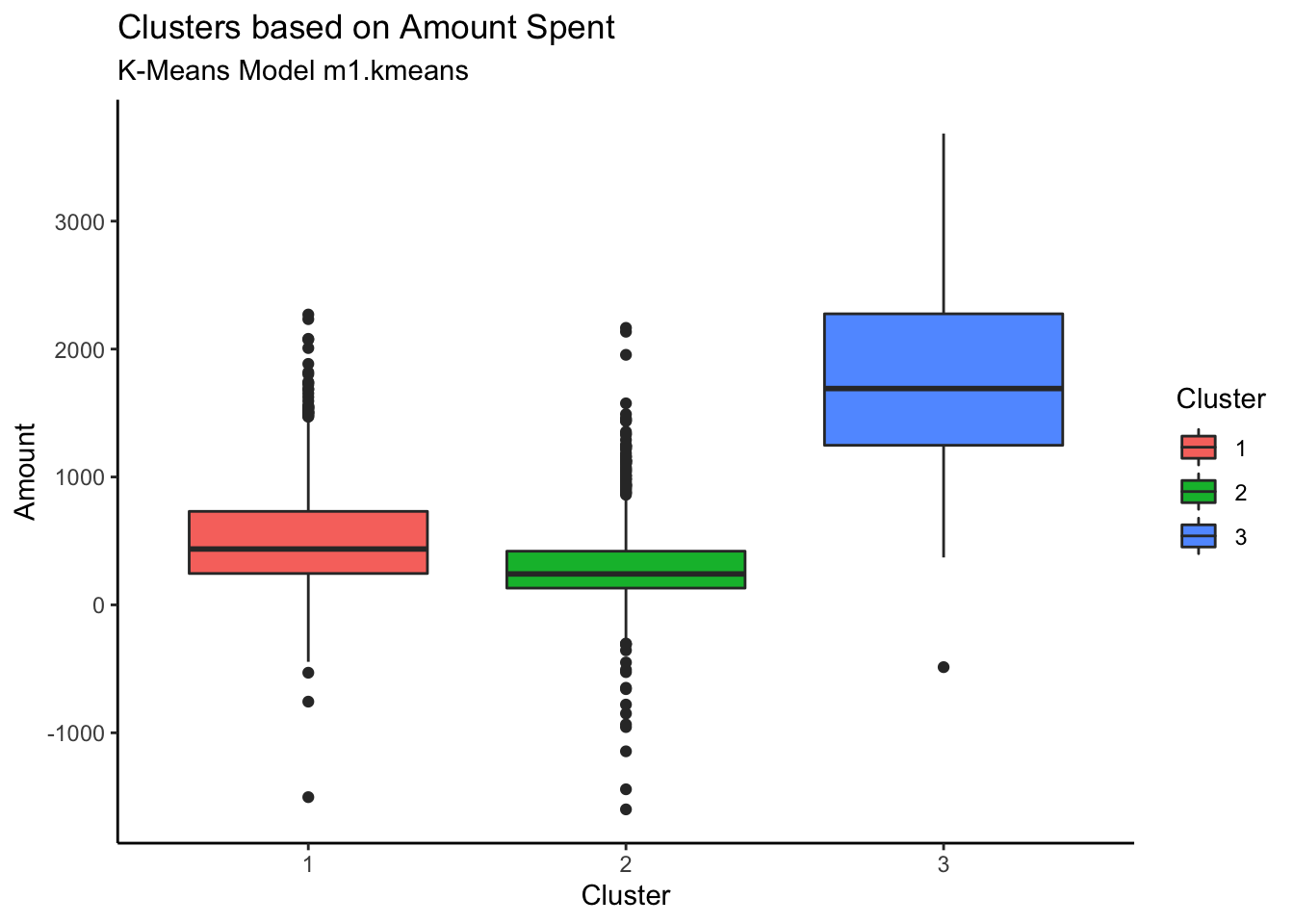
Customers in Cluster# 3 are spending more whereas cluster 2 customers are spending the least.
Code
customer %>% ggplot(aes(x=Cluster, y=Frequency, fill=Cluster)) + geom_boxplot() + theme_classic() +
labs(title = "Clusters based on Number of transactions", subtitle = "K-Means Model m1.kmeans")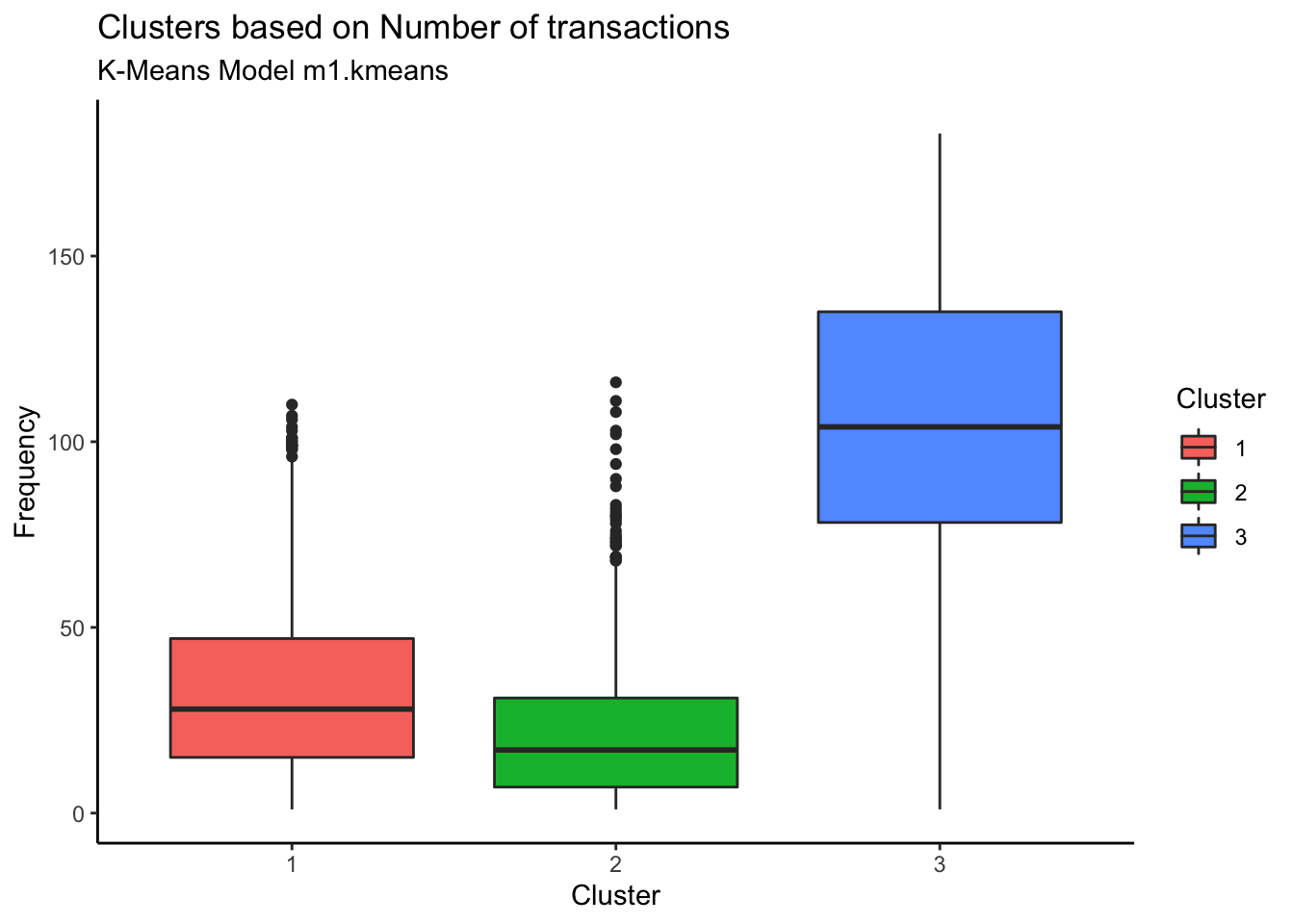
Customers in Cluster# 3 are most frequent customers indicating that the frequent customers spend the most.
Code
customer %>% ggplot(aes(x=Cluster, y=LastSeen, fill=Cluster)) + geom_boxplot() + theme_classic() +
labs(title = "Clusters based on customer last seen shopping", subtitle = "K-Means Model m1.kmeans")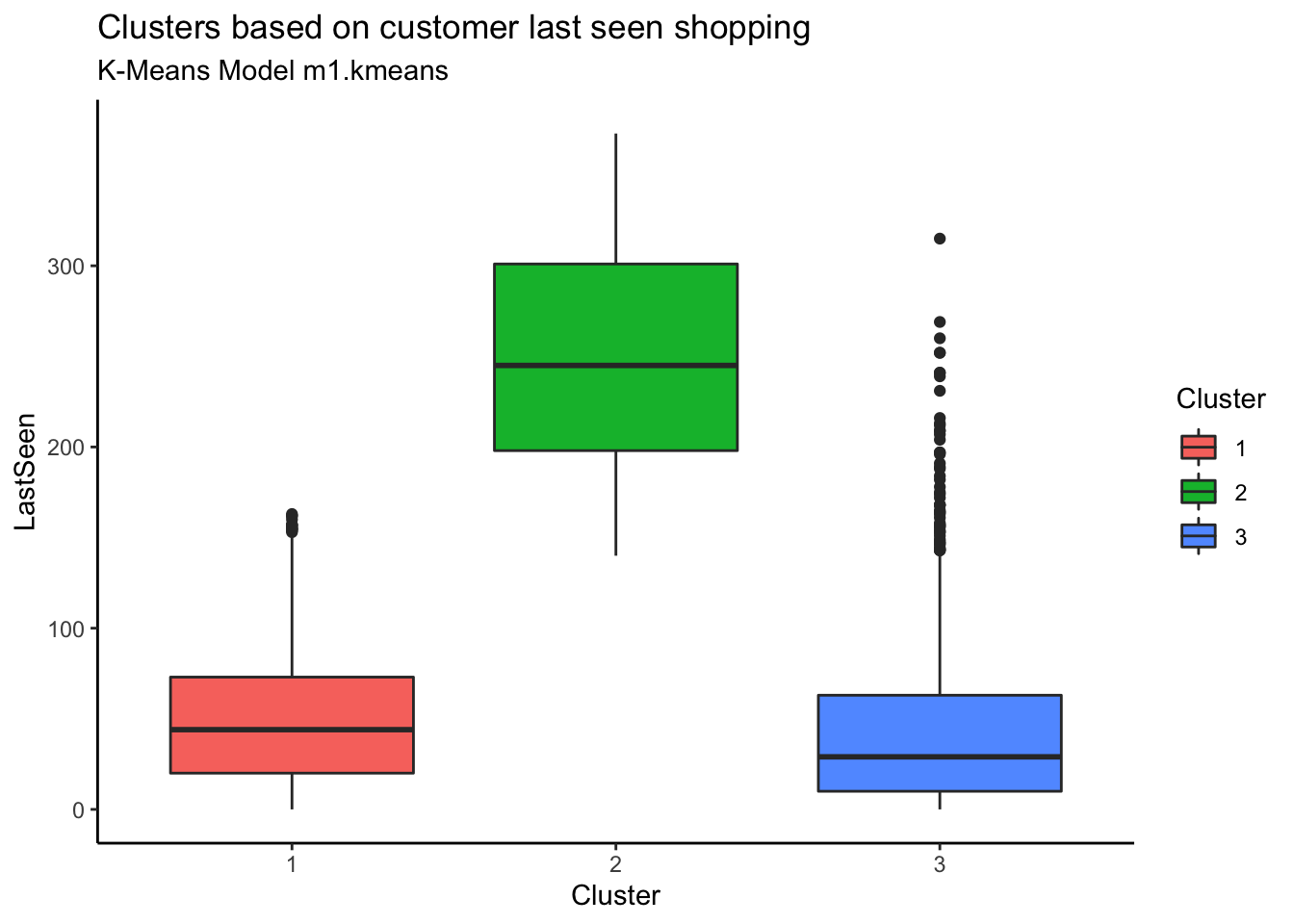
Customers in Cluster 2 have not been seen shopping recently. The most recently seen shoppers are in Cluster 3 and that also explains why they have spent more money and bought frequently.
3.5.3 Analysis
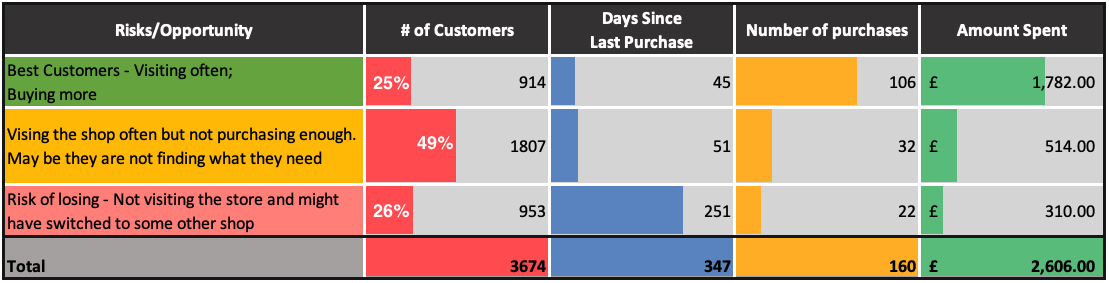
For this business, it is a matter of concern that most of their customers (49%) are not finding what they want. The shop would need to revisit their strategy of what brand/item they should be selling in the online shop to convert visits into revenue.
4 Conclusion
For businesses, the customer segmentation play pivotal role in identifying the customers by grouping them based on their buying habits and patterns. With increasingly large volume of transactions and unprecedented business activities, a clustering algorithm like K-Means is a great tool to achieve the segmentation of customers with speed and accuracy. In this paper, we have tried a real-time online business data to show how K-Means helped the business in identifying customers who are at risk of switching to other stores. We have also explained that there are multiple steps in the data mining processes and it started with data selection, then to data preparation, visualization, and finally to model creation and interpretation.
We also understand that K-Means is not always accurate and is dependent on initial choice of centroids and optimal number of clusters chosen. However, there are some improved algorithms that can help overcome these shortcomings.