K-Means Clustering
K-Means Clustering
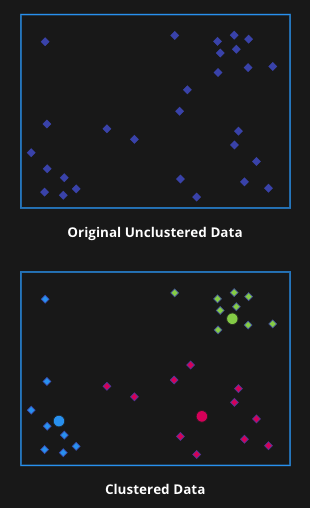
An unsupervised machine learning clustering algorithm
Data is clustered based on feature similarity
Unsupervised: Data is unlabeled, groups are unknown
Find similar groups, glean insights
Dataset may be very large and highly dimensional
Why would we need Clustering?
Main usecases:
A large unstructured dataset is to be clustered
without any instructionsNo prior information on how many groups we
might need to divide our data into
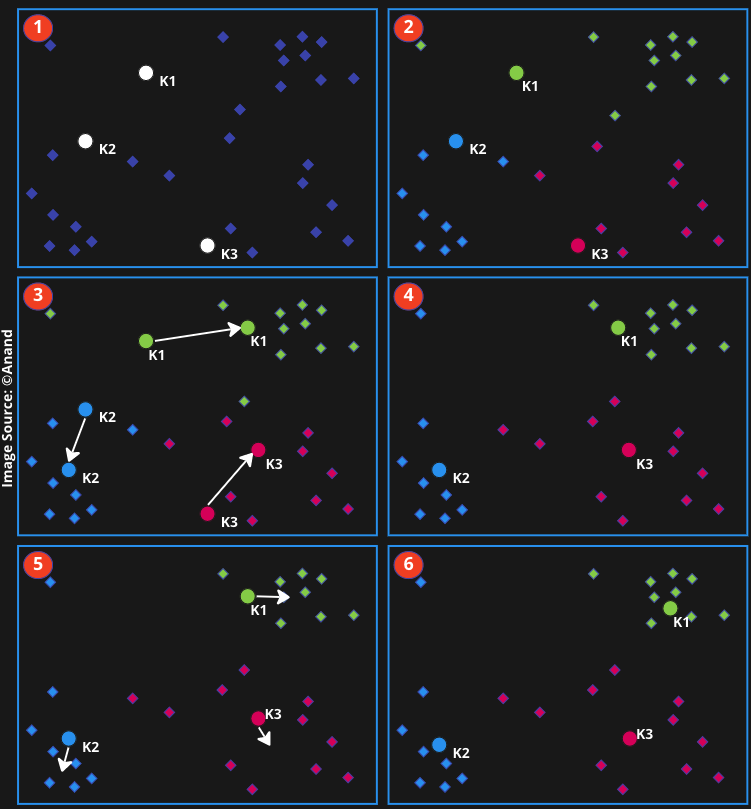
How can we create Clusters?
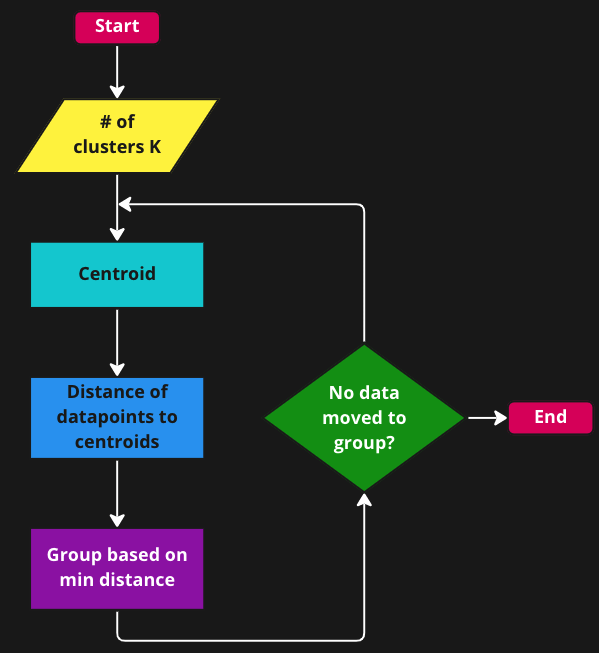

The Math behind K-Means Algorithm
- K-Means runs in an unsupervised environment and hence it measures the quality of the formed clusters by finding the variations within each cluster.
Where, K is the # of disjoint cluster \(C_i\), x is a data point in the cluster \(C_i\), \(μ_i\) is the mean of the data points in the cluster \(C_i\).
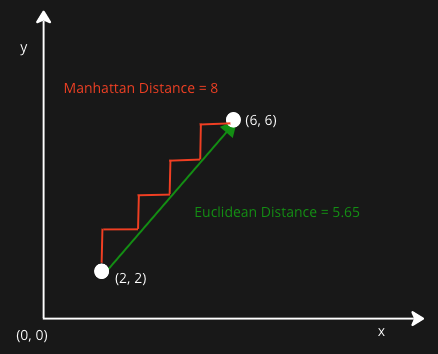
K-means calculates proximity between data points
and centroids to place the data in appropriate cluster.Euclidean distance
\[ D_{euc}(x, y) = \sqrt{\sum_{i = 1}^{n}{(x_i - y_i)^2}} \]
- Manhattan distance
\[ D_{man}(x, y) = \sum_{i = 1}^{n}|(x_i - y_i)| \]
Our Business usecase
Customer Segmentation
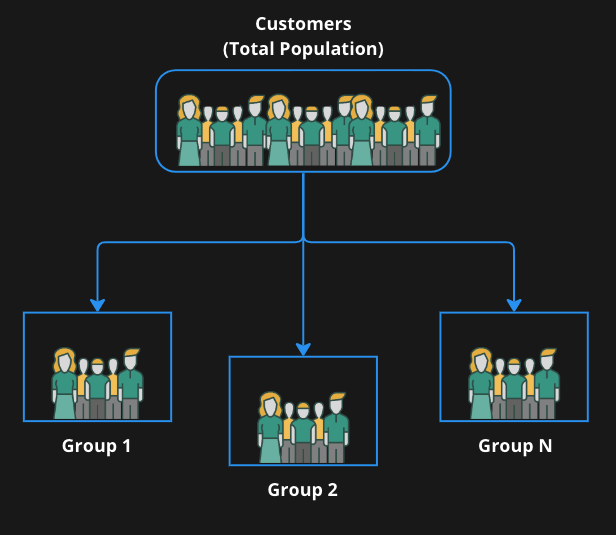
Dividing customers into number of focused groups that are as dissimilar as possible across groups, but as similar as possible within each group in specific ways with shared buying characteristics that is relevant to marketing
The chosen attributes will play a key role in deciding the groups.
Algorithm is based around analyzing what we call RFM - customer recency, frequency, and monetary values
Our Business usecase
Data Visualization
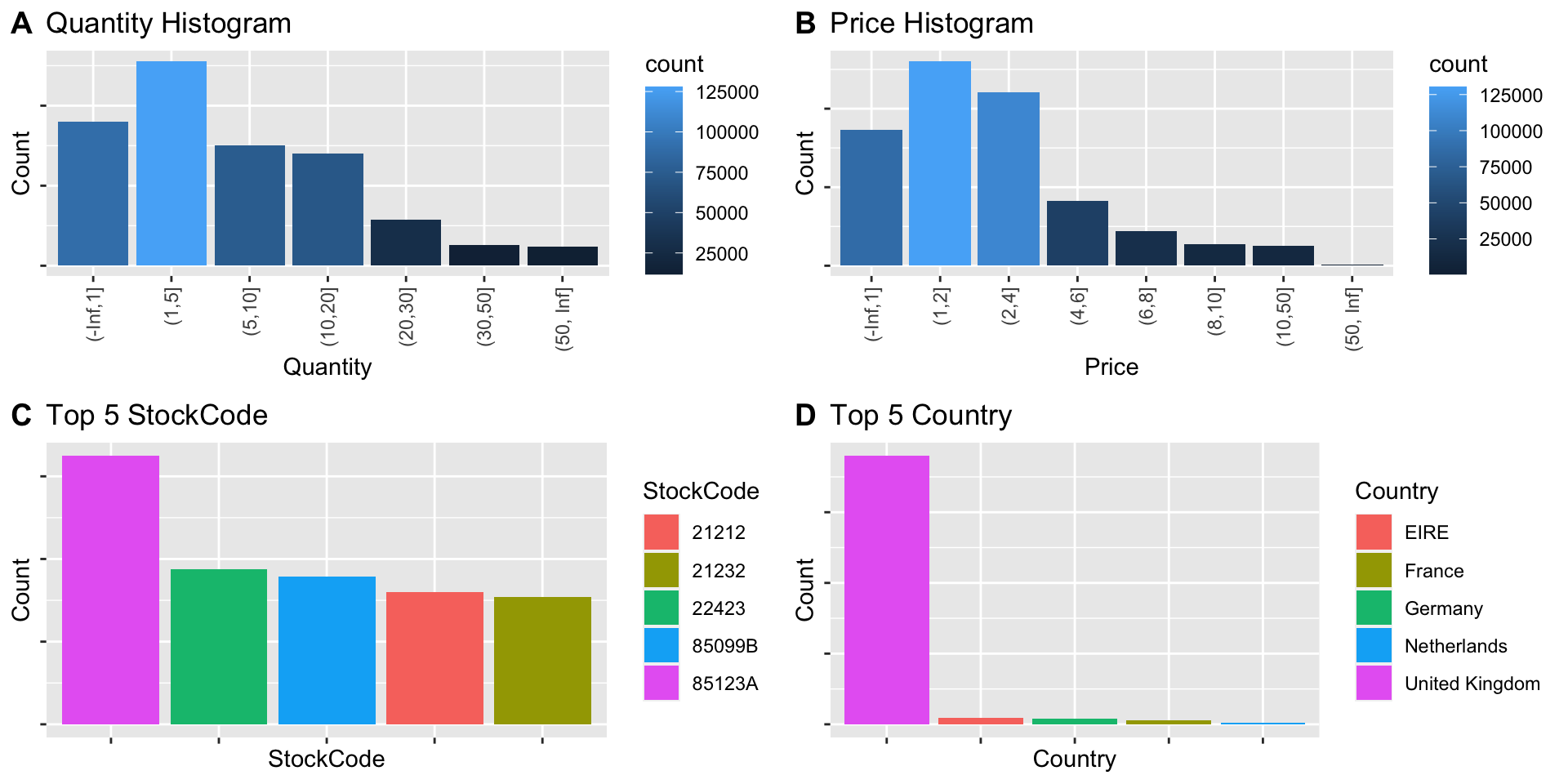
The Quantity is heavily skewed right and most of the transactions involved a quantity in the range of 1 to 5
The unit Price is also skewed right and most of the items have unit price between 1 and 4
The item with StockCode 85123A was sold most
Most of the customers belong to United Kingdom
Our Business usecase
Data Preparation
- Remove missing values
2. Select only required attributes - CustomerID,
Invoice, Quantity, InvoiceDate and Price
3. Create a new attribute Amount
- Group by customer id and count invoices
- Create a new attribute LastSeen
data$LastSeen =as.integer(difftime(max(data$InvoiceDate),
data$InvoiceDate, units = "days"))
#Group by customer id and take min of LastSeen
customer_lastseen <- as.data.frame(data %>% group_by(CustomerID)
%>% summarise(LastSeen = min(LastSeen)))- Merge the above data frames to get unique customer and their total amount,
frequency of visit to the store and the LastSeen shopping in the store
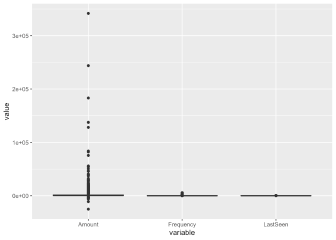
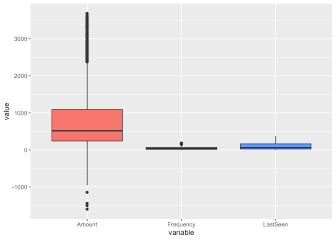
# create detect outlier function
detect_outlier <- function(x) {
# calculate first quantile
Quantile1 <- quantile(x, probs=.25)
# calculate third quantile
Quantile3 <- quantile(x, probs=.75)
# calculate inter quartile range
IQR = Quantile3-Quantile1
# return true or false
x > Quantile3 + (IQR*1.5) | x < Quantile1 - (IQR*1.5)
}
# create remove outlier function
remove_outlier <- function(dataframe,
columns=names(dataframe)) {
# for loop to traverse in columns vector
for (col in columns) {
# remove observation if it satisfies outlier function
dataframe <- dataframe[!detect_outlier(dataframe[[col]]), ]
}
return(dataframe)
}
# detect_outlier(customer$Amount)
customer <- remove_outlier(customer, c('Amount','Frequency','LastSeen'))Our Business usecase
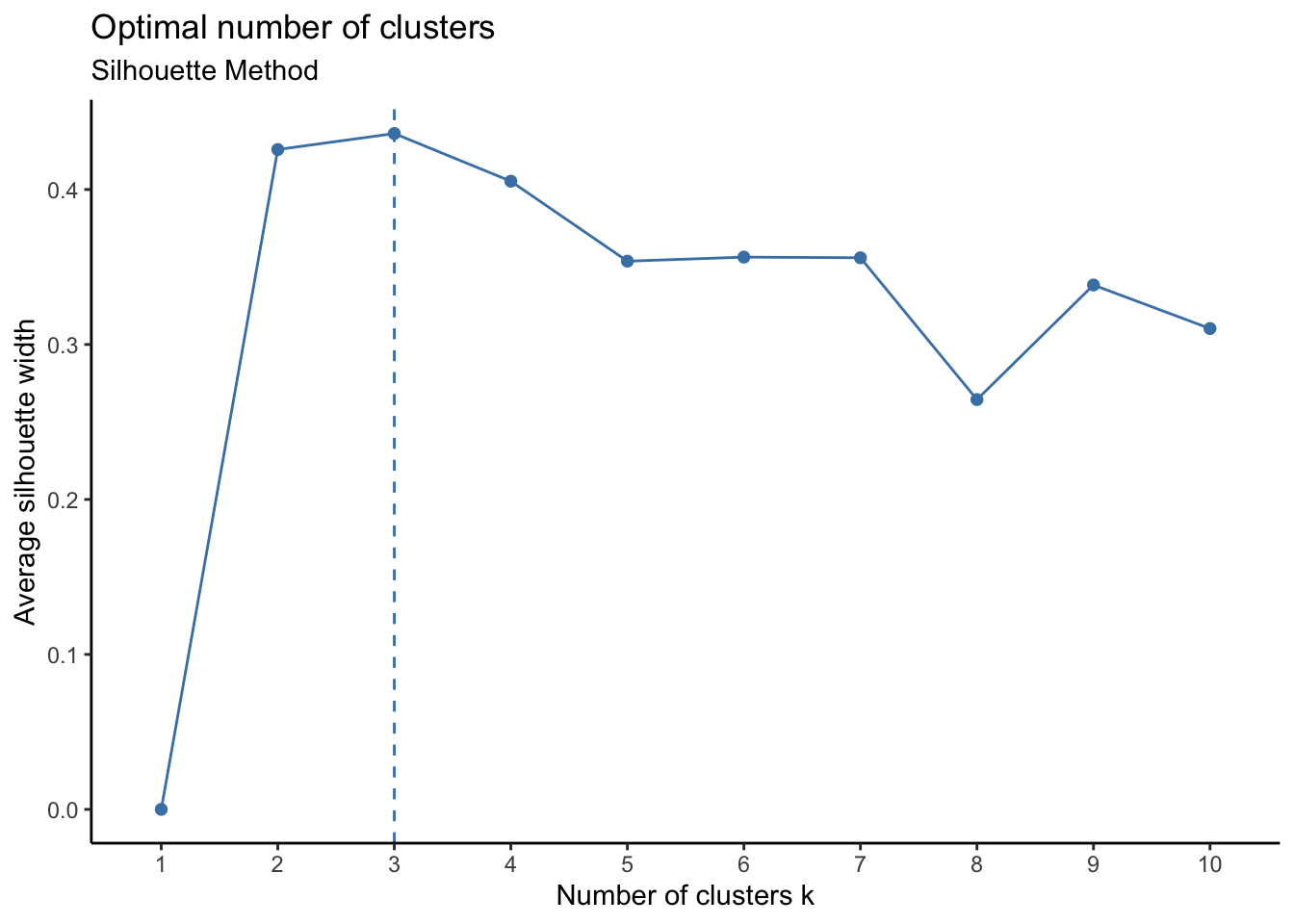
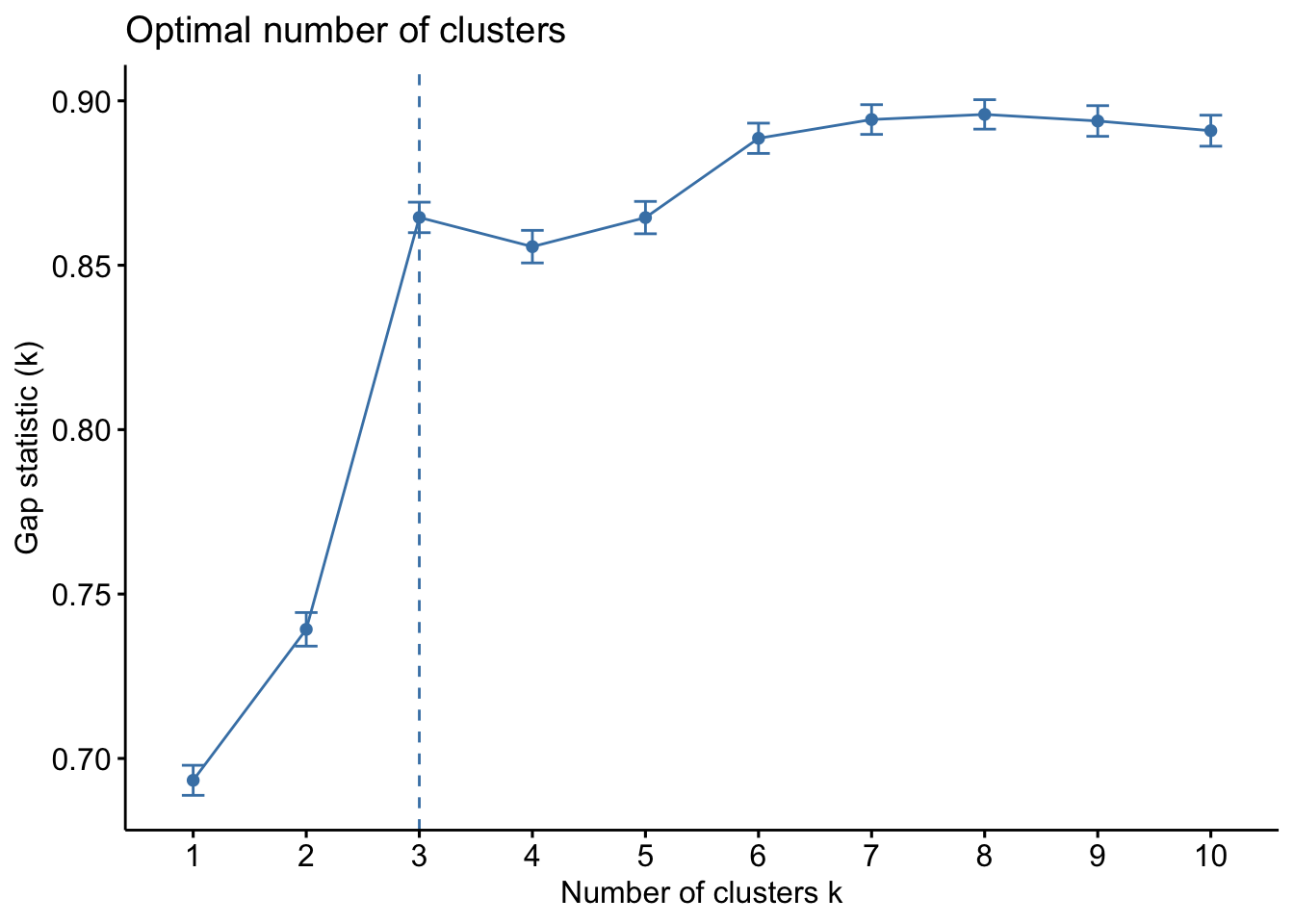
Statistical Modeling: Optimal # of Clusters
The reliability and the performance of a clustering algorithm is directly affected by the initial choice of the number of clusters (K)
fviz_nbclust(customer, kmeans, method = "wss")
+ geom_vline(xintercept = 3, linetype = 2)
+ labs(subtitle = "Elbow Method")
- Calculates values of cost with changing K
The larger number of clusters implies the data points are closer to the centroid
The point where this distortion declines the most is the elbow point
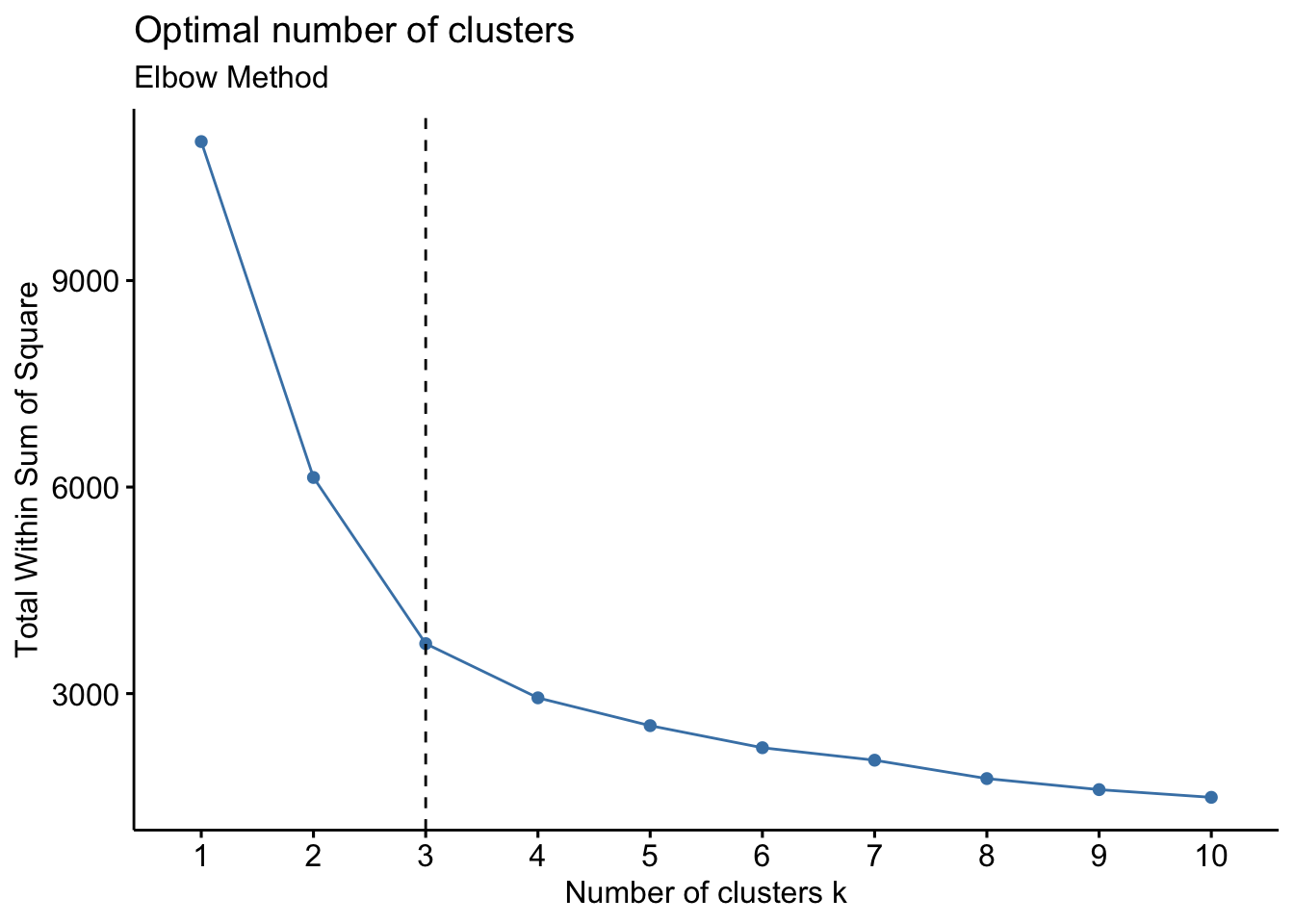
The Business Value?
Results and Analysis
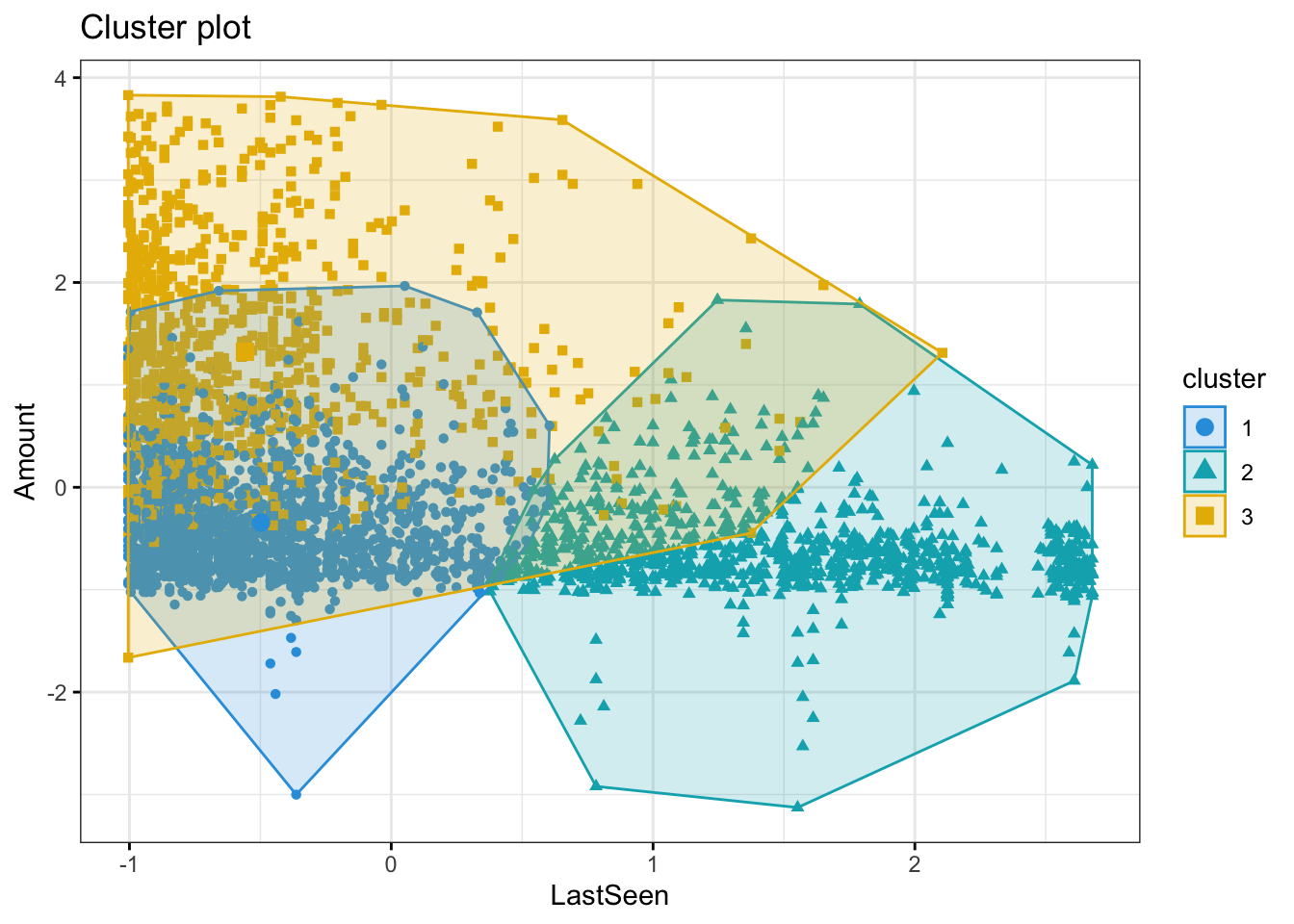
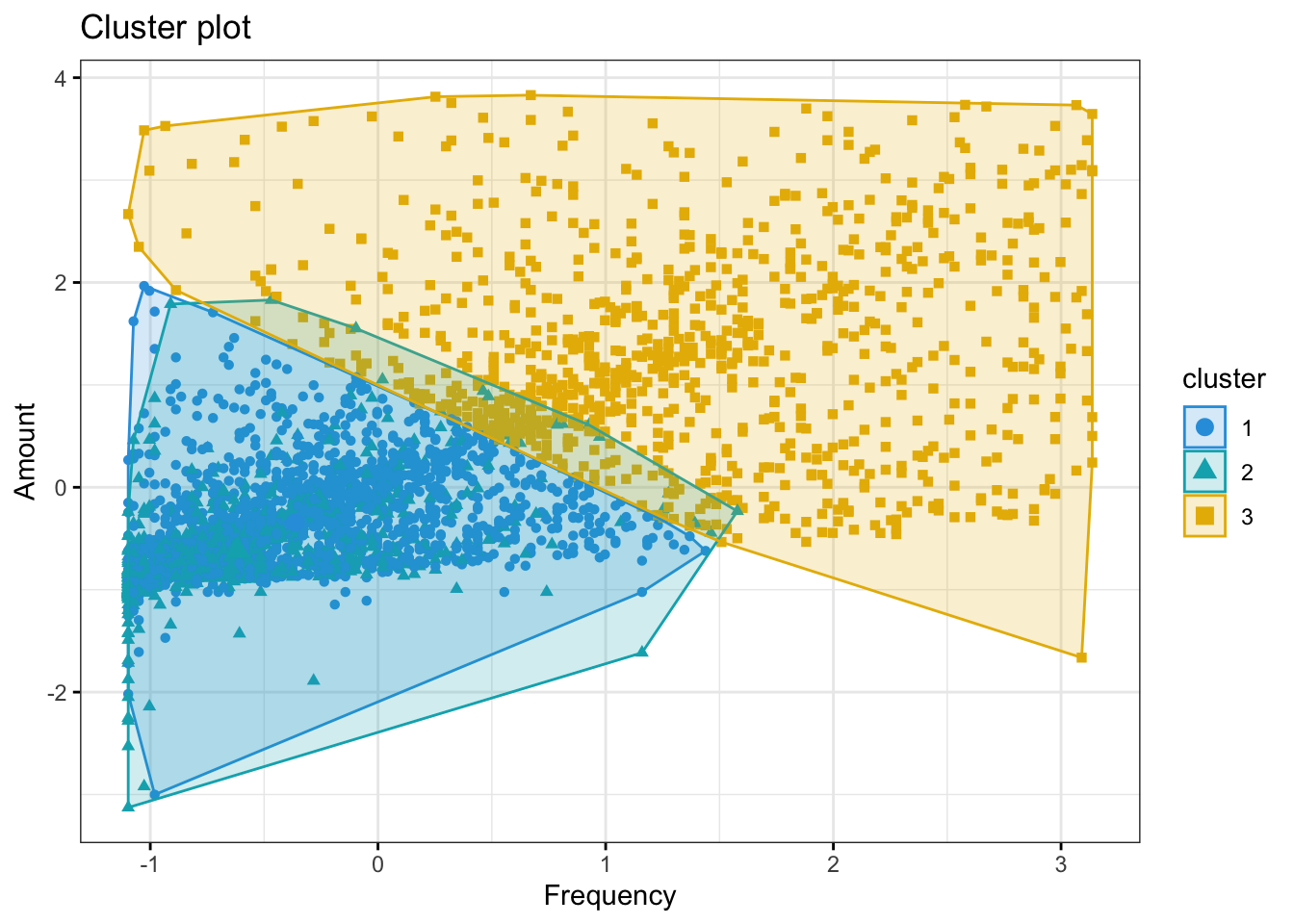
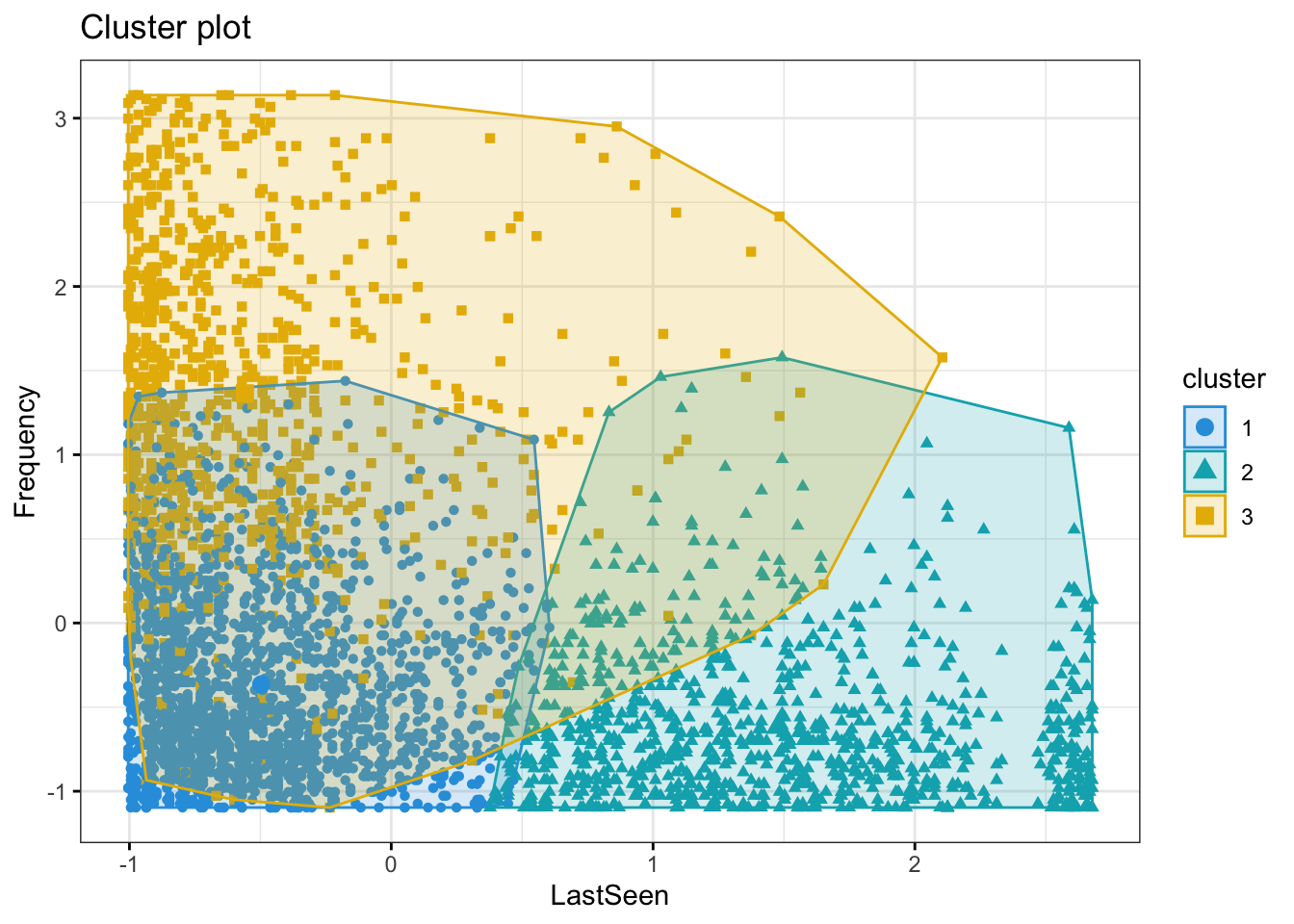
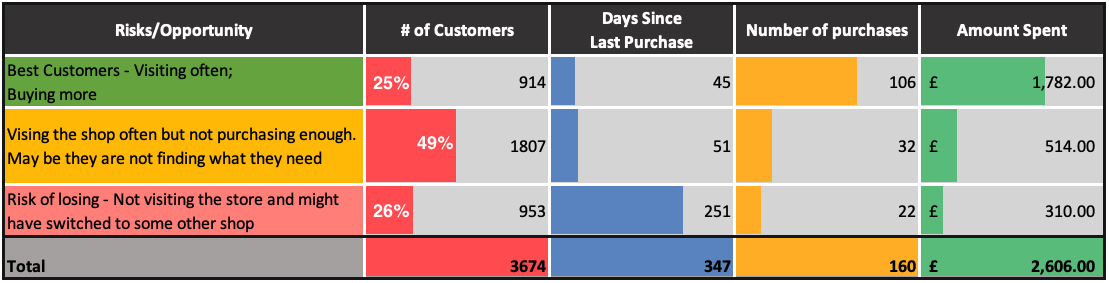
The clusters 1 and 3 are seen in the store often. Cluster 3 customers are spending more whenever they visit. Cluster 2 not seen recently so spend less
The Cluster 3 are more frequently buying and hence spending more. Cluster 1 and 2 are almost having similar trends in terms of number of purchases and amount spent
The Cluster 1 and 3 are seen buying often and whenever they are seen buying, they make lot of purchases
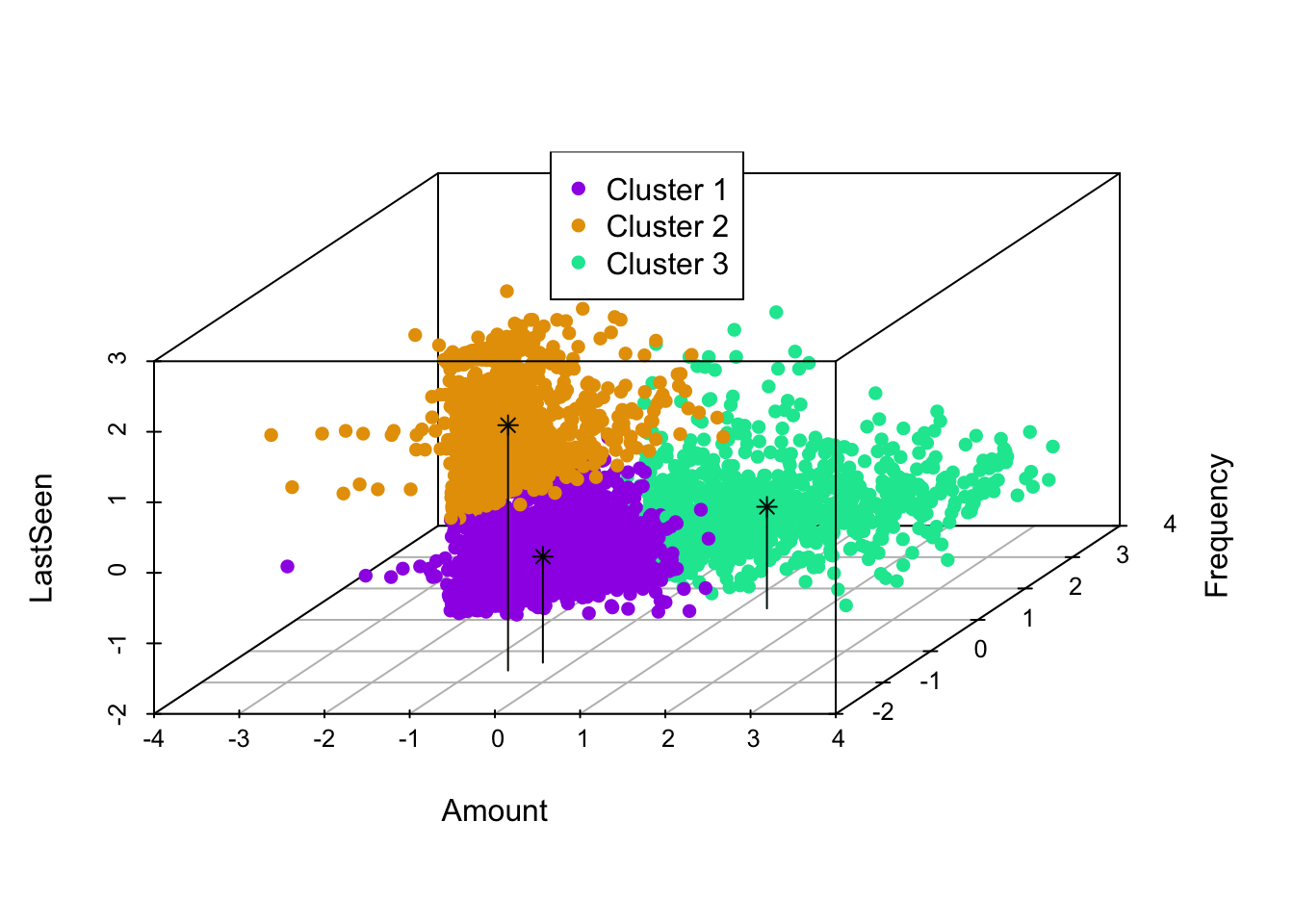
The customers in cluster 3 are seen shopping often, they spend more,
and they purchase frequentlyCustomers in cluster 2 are of concern. They do not visit the website
often but spend almost like cluster 1 and purchase as frequently as cluster 1.
So, we can either target cluster 1 to make them buy when they visit store
(since they are visiting often but buying less) or make cluster 2 visit often
as they are buying more when they visit but visiting less.
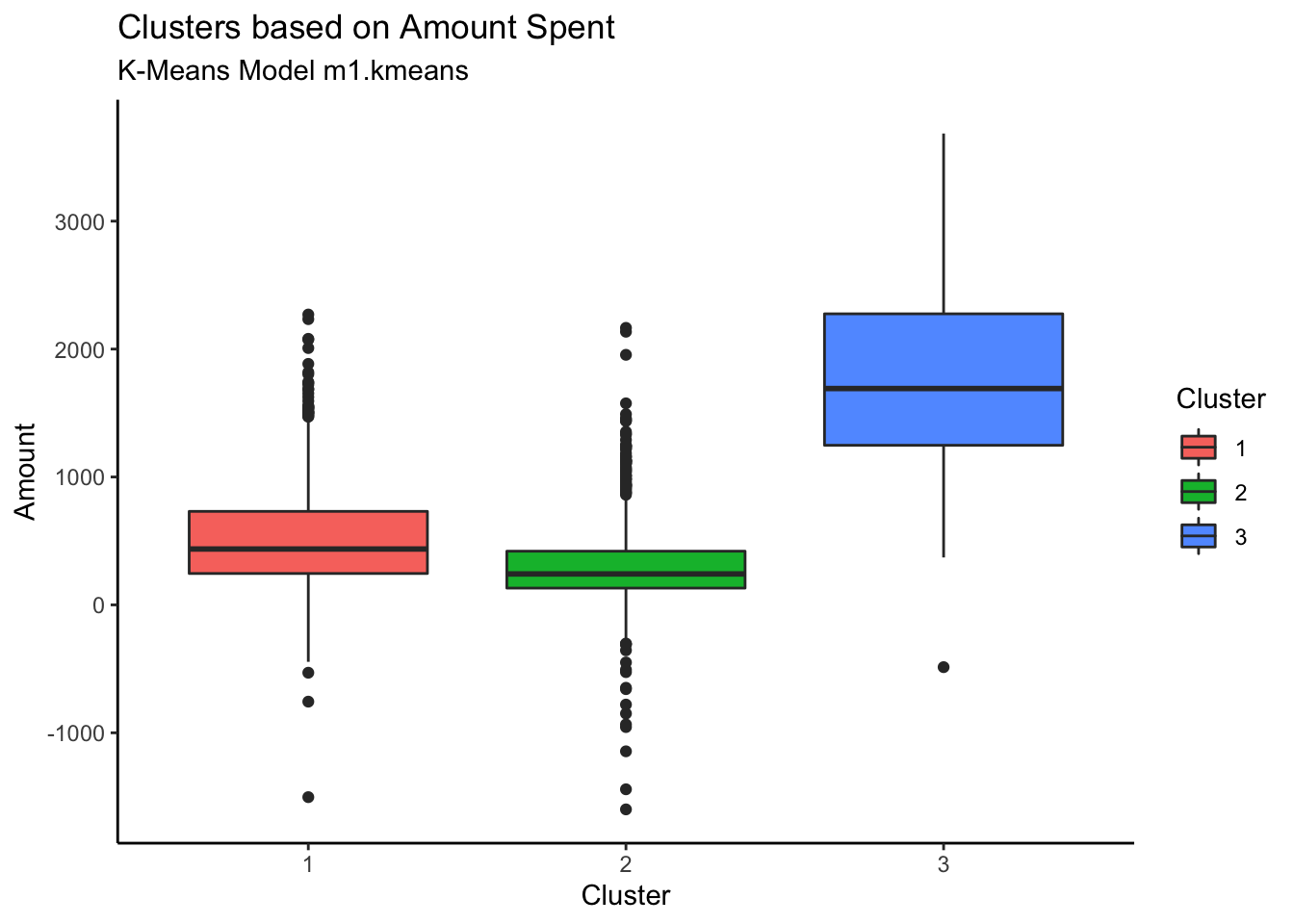
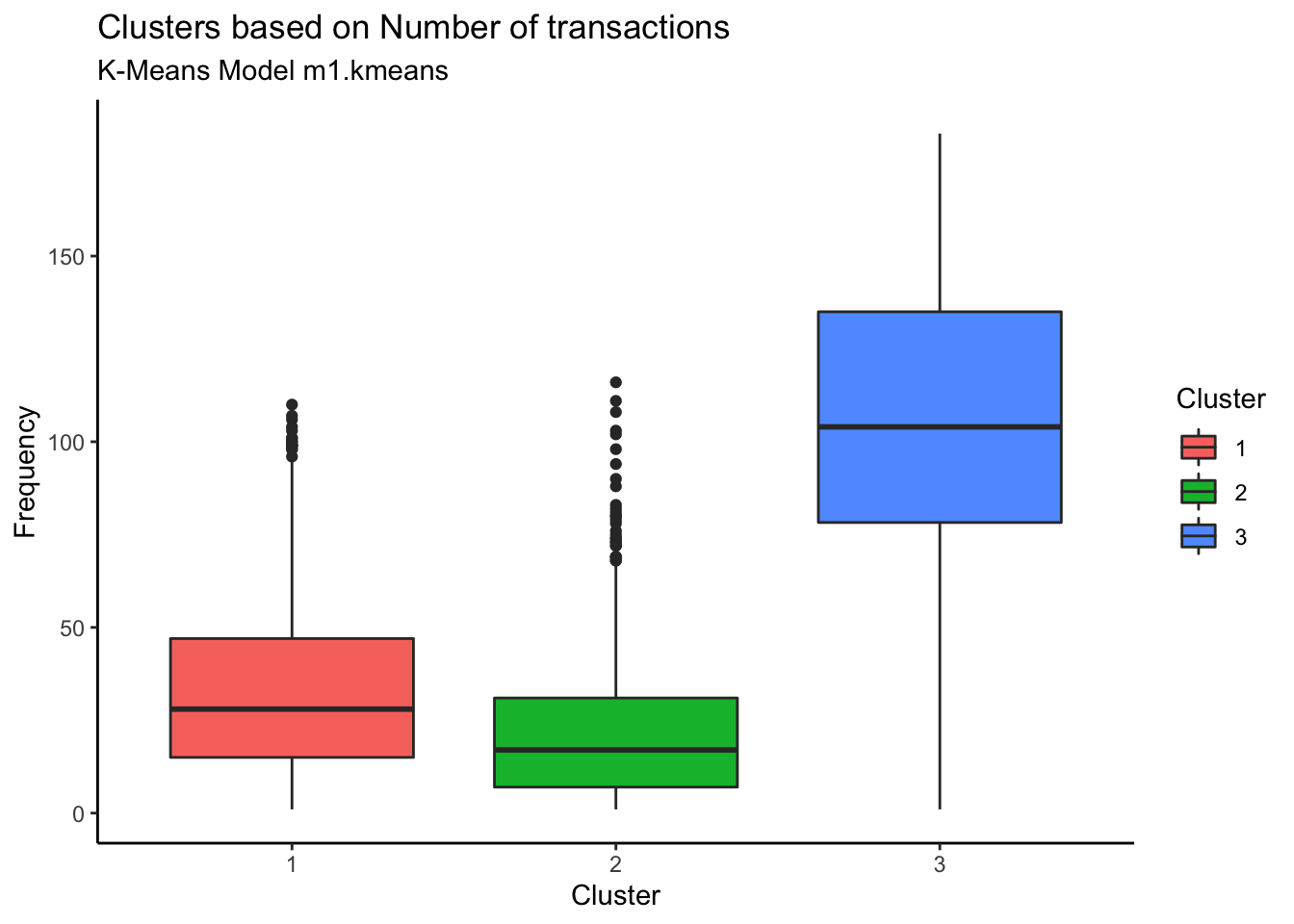
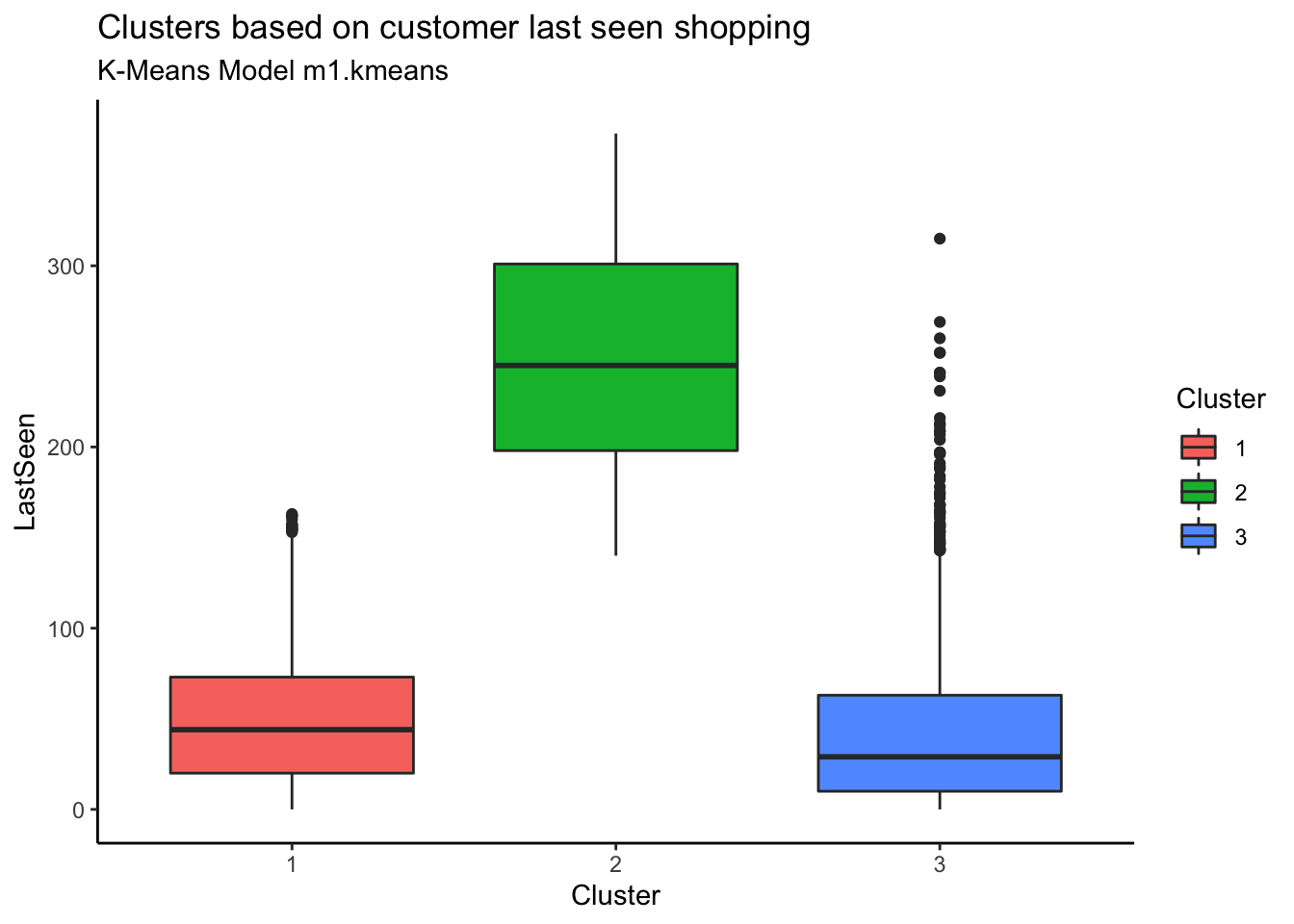
Customers in Cluster# 3 are spending more whereas cluster 2 customers are spending the least
Customers in Cluster# 3 are most frequent customers indicating that the frequent customers spend the most
Customers in Cluster 2 have not been seen shopping recently. The most recently seen shoppers are in Cluster 3 and that also explains why they have spent more money and bought frequently